CompTIA Security+ Chapter 1 : Threats, attacks and vulnerabilities
Table of contents
| Sections |
|---|
| 1.1 Indicators of compromise and malware |
| 1.2 Compare and contrast types of attacks |
| 1.3 Threat Actors |
| 1.4 Penetration Testing |
| 1.5 Vulnerability Scanning |
| 1.6 Impact of Vulnerabilities |
1.1 Indicators of compromise and malware
IOC’s (Indicators of compromise) refers specifically to the unauthorised activity that shows a breach in the information system, we reach the conclusion that something is an IOC if no reports of the incident or statements by staff see it as a technical fault in the system i.e something has happened outside the scope of common error to leave this system compromised. If a system admin has messed up one of the servers causing what would look like an outsider buffer overflow attack for example, he would probably report it to the boss and begin fixing it. If he didn’t alert management, then it would look like that sort of attack, and it would worry the higher-ups that their system had been compromised ; or even worse, it was an insider trying to get information! So remember, an indicator of compromise is the “scar” , the signs etc, left on an information system showing that it has been compromised to some degree by some malevolent agent.
The scars on the system act as breadcrumbs to an incident response team, and depending on the service(s) that look to be compromised they give the team of idea of how the attacker got in and what they leveraged. This is central to building up a picture of the overall state of the system, and with the other clues given to us, combined with things like old snapshots to compare, we can estimate how much money we’re about to haemorrhage…
Commonly observed IOC’s
Lets go through some scenarios where we have to discern how much of a threat this indicator appears to be. I would say one of the highest is outbound network traffic, due to the fact as system admins we know all of the IPs of our users practically by heart, and seeing one of our users who usually only talks to the other computers on his local subnet start making heaps of outbound messages to some rogue IP … Yeh I would start to worry. Web traffic specifically can be a tell-tale sign, as hackers commonly use directory busters, which involves sending thousands and thousands of requests, for mostly bogus folders, but nevertheless we want to be alert to these sorts of things. We might often see this kind of “non-human” behaviour, requests that go every 15 seconds , or our entire web server cluster being constantly queried every millisecond… those sorts of requests are too much for a single human to do, and hence give their game away (that is , if we are looking!).
Web traffic, and traffic in general in high quantities might give the system admin the impression that an attacker is trying to execute a DDoS attack, but it might also be that we are experiencing a period of high demand. It depends what service is being overwhelmed with traffic, and the time , requester origins etc. If it’s a Black Friday event then this is a common cause of outage for many companies :/
The next one is privileged user account activity, which is more obscure and it may just be that I misconfigured a user, though it might be that an attacker has gotten inside one our client computers and escalated their account privilege, to launch an attack. So we have to dive a little deeper and figure out the intent of the privilege, is this user just accidentally accessing files because I gave him the ability to , or is it from a more malicious curiosity? Either way, I need to narrow this down and patch the account quick!
Next would be geographical irregularities. This is quite straight forward. If an attacker were to spoof one of my client computers, and I start noticing what should be the everyday requests from the US start coming from China, then I have good grounds to think that account has been compromised.
Account login red flags If someone starts logging into the company portal from Vietnam, where we have no offices, now is the time to start fixing. What can also happen is the constant attempts to try logging into accounts that don’t exist, and when this shows up in the logs it smells very strongly of a brute-force attack.
Increases in database read volumes, now unless we have a new product going out and we expected some kind of rise in the amount of end-users accessing our databases, we might want to check it out. A company also has many different data repositories, which all differ in their sensitivity, so if we see a great influx in the amount of sensitive corporate data going out , then bingo… Most attackers who were smart enough to break are also smart enough to slowly bleed information out of a system , to mimic normal traffic and so it is worth keeping a tighter grip on the more sensitive databases, maybe with human oversight, and the general encrypted databases might suffice with strong logging and good authentication. We might see bundles of this data moving along subnets into the network that connects with the real world, and if we do these folders , maybe in a /tmp folder or something then this gives us a pretty strong indicator someone is trying to smuggle data out.
Large numbers of requests for the same files would indicate to me that a spider has been launched which is trying to scour our directories and is probing the access level of different files. Not good at all.
Mismatched port-application traffic, including encrypted traffic over plain ports. If an attacker is sending their virus over the wire, maybe over something weird like FTP which we commonly reserve for plain, boring word documents then that might raise some eyebrows; also if we see an account establishing an SSL session with a client computer on port 820 then this would be another cause for concern, unless of course that is the port you chose to serve SSL on.
Unusual DNS requests coincide with network irregularities , if someone is crawling over our side , meticulously looking for a gap in our configurations, i.e hoping to hijack our records and start pointing his/her own site, then this is someone who wants to do some damage…
More local system now, what if we saw that a user’s registry was changing? That the Windows Registry now allowed some random program called stealalldata.exe to run after logging in …
Moreover, if we find that a client’s computer has the latest updates and patches installed, without my go-ahead, then it is highly likely that a hacker has not only gotten into the system, but patched it to make us evermore certain that our system is rigid; but in actual fact our system is incredibly weak, and now we have no idea where to start looking , which avenues were broken into as they have all been fixed… This is also done to keep other hackers out who were also hoping to steal a piece of the pie.
For mobile devices, it may be that an attacker goes after them in order to change their profiles, maybe their IP to spoof to another client device, so that when they walk to another department then they can connect, and the malware present on the phone has a chance to scan the other clients, and the next phase begins…
Remember, that unless you have the ability to log, know what the expected behaviour is and educate your staff, then this might not be a strong enough indicator of compromise! Does the whole thing have to explode for you to notice it? With more logging and intrusiveness into each client computer comes total control, and the management of every feature which of course makes it very hard to control, but then we completely do away with trust and privacy, it depends on the device the client uses, and maybe some scars we know not to be a “big deal” and easily correctable…
Frameworks for sharing Indicators of Compromise
What I mean by sharing IOC data is that organisations that are in the same industry, maybe data sensitive sectors like finance, have a system where they can publish new tactics that attackers are using , new “signatures” of malware and such to alert other system admins about a potential breach.
The two main frameworks are:
OpenIOC
Created by Mandiant , and written in XML, this is a framework used to facilitate the sharing of IOC data. This is an open source piece of software.
STIX/TAXII/CybOX
Structured Threat Information Expression (STIX), Trusted Automated Exchange of Indicator Information (TAXII) and the Cyber Observable Expression (CybOX) . These services are all written by MITRE and are designed to specifically facilitate the automation of information sharing between organisations. It’s written in Python amongst other languages…
Types of malware
Malware is a piece of software, or multiple pieces, who have the sole aim of doing something nefarious, in any degree of subtlety.
A polymorphic piece of malware, is malware that changes its code after each use, making each replicant different for detection purposes.
A virus is a piece of code that replicates by attaching itself to another piece of executable code. It uses the executable as a primer, and this will execute the virus itself in the process. It needs a user to click on a button, or some sort of code to refer to this program in order to get going; A worm on the other hand needs no such primer, and this is what makes it a lot more infectious as it has the instructions built in to spread from client to client, and bears within itself the robustness to replicate.
An armoured virus is one that wraps its source code in an encryption layer, so that a reverse engineer hoping to dissect this virus , in order to stop it, first has to break through this layer of encryption…
Crypto-malware is the beginning of the end, and it is the first step used by ransomware, which is to encrypt pretty much the entire disk (save the boot sector and the virus itself) and this wrapping prevents the user from accessing any files, and hence creates a terrifying denial of service. Ransomware leverages this encryption, and this process being included is assumed to be automated, and now the attacker shows the “popup” demanding a ransom in exchange for resumed access to their files (the encryption key).
A trojan is what it says on the tin really. A program masquerading as something that a user would want to click on, something that doesn’t seem malicious, and hides within the veil of amicability , only to strike , using any combination of system vulnerabilities and exploits. They can be installed just by clicking a link on a malicious website and download “free antivirus” , at which point the trojan now has access . Remote-Access Trojan / Remote Administration Tool (RAT) is a toolkit , which is again masked as helpful software, designed to create an avenue of access to remote users. It goes beyond the normal functionality of a trojan and aims to be a second admin essentially, having a grasp on every peripheral, logging all inbound and outbound traffic etc. It differs from a backdoor as these are usually separate to hacking efforts, are quieter and they are used to regain entry when their initial access has been found and patched. RATs are remotely accessing the system as part of their exploitative efforts and can be used to setup Advanced Persistent Threats (APTs), which are typically used by nation states over a sensitive system, to allow them to drain as much data as possible.
A Rootkit is a form of malware designed specifically to modify operations on the operating system to allow non-standard functionality. It contains malicious software where the aim is to get root access for the hacker, hence the “root” part, using a “kit” of different tools. There are a few forms of rootkits, depending on where the attacker wants to gain this root level access:
- Hardware or firmware rootkit. This is where the malware aims to infect your UEFI/BIOS and this would be very hard to remove with conventional tools which work at the Operating System level and above.
- Bootloader rootkit. A bootloader is the piece of code that will call your Operating System kernel and from there the OS is loaded into memory. A bootloader rootkit will want to be called at the same time as the OS , making it almost impossible to be detected by standard antivirus. Trying to remove this malware may also be challenging as it could be linked to other boot records.
- Memory rootkit. This is a type of malware which loads for a brief period of time in RAM , running harmful procedures in the background but they should be gone if you reboot your system. Such rootkits usually come from malicious websites without the need for you to download anything.
- Application rootkit. This is where some files that make up that application are replaced by malicious copies, which will run functions that make use of the fact this app is running with root access. Now it is the task of the attacker to persist this access and hence change the system to allow this. If you were to load Word or PowerPoint it would look normal, but in actual fact you have executed some background scripts which are wreaking havoc.
- Kernel mode rootkit. This malware has the purpose of altering your Operating system and changing key functions to accommodate the attacker.
The actions a rootkit must take should automatically invalidate the systems specification, and an indicator of compromise flag should be shown to the system admin, who takes subsequent measures; on the other hand though, a good rootkit is one which “only just” steers the system configuration into malevolent grounds, making its true purpose ambiguous and hence harder to discern. It is simply a battle between rigid and complete system understanding , versus the ability to leverage existing functionality in quiet, nuanced manners.
Keylogger. Logs keystrokes to a file, and back to the hacker…
Adware is usually legitimate, what normally happens is that in the end-user agreement, there is a negotiation where the user gets the product for free, maybe this is a mobile game app, and every ten tries or so when the character dies an advertisement plays. Unfortunately though adware starts to stumble into the side of malware when there is such a degree of advertisements playing that it is considered excessive, overbearing , or the adverts themselves are extracting too much data from the user. Companies like Google and Facebook have been accused of pushing their advertising to the point of adware, due to its intrusiveness and that they leverage the fact the user consented to all this as legal reasons behind this bombardment. Adware backed by law, though completely void of morals. Spyware is nefarious adware taken to the extreme , and through these mediums they can record the user’s screen, steal user account information, take screenshots etc. Spyware might also be separate though, and embedded with other pieces of malware, for example a rootkit might be used to grant universal access to things like the webcam, to turn it on and disable the blinker, so that the spyware can quietly stalk its prey.
Bots are systems that have been taken hostage by a piece of software and will now perform tasks, under the control of another program. Bots are commonly used by hackers to orient a lot of victim machines towards a server, and direct a multitude of requests towards it, in hopes of bringing that server down.
All these types of malware can work together. For example, a worm can scour a host of public cloud servers looking for default configurations to certain services, like guest accounts, and within this account plant some ransomware and move on.
1.2 Compare and contrast types of attacks
The three main “platforms” for which most attacks are waged is either on the victim computer, which is a purely technical operation, over a network which involves enumeration and the understanding of the conventions employed by that network to communicate, and the highest “platform” is the human level, which involves social engineering attacks, like how we can spoof a call as a help desk worker and get the user to damage their own system for us, making it a lot more hackable; however, human-targeted attacks can also be extremely low-level like USB-drops , which doesn’t require the leveraging of a client computer and/or a network to communicate with the person.
This last attack method mixes social engineering with the purely technical aspect of privilege escalation, then code execution (the malware inside the USB). Pretty much all attacks nowadays employ a combination of human-based trust, network-based access and client-based exploitation; moreover attacks can be directed at a single target, but they have to wade through many layers to get to them and their goal.
First off, I’m going to talk about the types of attacks where network-based access is irrelevant and the malware itself focuses purely on exploiting a client’s computer. Device driver manipulation is where an attacker hopes to switch out a device driver for another, bugged version, or to simply inject some malicious code into that driver which breaks the communication between it and the device, and it with the operating system. Take microphone for example, if I replaced the driver the client has installed for one which also logs the output into a separate file, then this would be driver manipulation; The problem with these types of attacks are many, the most problematic being just how “loud” it is, as the Operating System will likely tell the client that the connection has been interrupted somewhat, and also the complexity of the hack itself can oftentimes be overwhelming. If you are able to pull it off though device drivers offer an insecure avenue to peripherals and maybe even computer internals. It is for this reason that Operating Systems have “signed drivers” which means they can detect when changes are made, as the hashes of the previous driver version and the new malicious one are different, and hence communications are shutdown. Shimming is where code is put between the Operating System and the drivers, usually to translate between the two formats (of the OS and the driver) but like anything else, attackers have found ways to exploit this translation…
Refactoring is where a code base gets updated , usually for readability and optimisation, not so much for functional rewrites (causing a change in the external behaviour of the code). With codebases that are quite “rough” get optimised, hackers have found ingenious ways of providing slightly altered algorithms to the update, which do in fact cause additional functionality, the simplest and the most subtle would be a buffer overflow, which can then break the application. Buffer overflows are used all the time by attackers, particularly on poorly designed web applications, but a program of any reasonable complexity need to iron-out this potential edge-case. It happens when a variable, or any input buffer (like the input fields within forms on websites) receives too much data, more data then the buffer has been allotted to handle, and then this “spills” onto neighbouring addresses and if an attacker were to have a piece of code, which when spilt into an address that has an admin regularly accesses can then be run as an admin…
With this I move into the more network-based , and browser reliant attack types…
Injections are very much like buffer overflows , but they are more specific to input fields. Injections are where a hacker enters a specific type of input, most common is an SQL request , which goes to the backend database and pulls out data , which shouldn’t be allowed as the application developer needs to sanitise the input more thoroughly. If inputs are left unchecked, then attackers may even be able to gain command-line access to the underlying server, depending on the type of input that is, and execute commands at the same privilege level of the application itself.
Keeping to the topic of poor input validation within browsers, comes the slightly more sophisticated Cross-Site Scripting (XSS) attack. This is again relying on poor input sanitisation , but for the purpose of including their script within the input and having that be executed as part of the “chain of evaluation”. There are three different types of XSS attacks that you should be aware of, and the properties which distinguish them:
- Non-persistent , or reflective XSS attacks: Here the injected script is not stored on the backend, but immediately executed and passed back via the web server, so part of an evaluation chain only.
- Persistent XSS attacks: As you can probably guess, this is where the script itself does persist on the web server, or within some external storage system. What this might mean is that each time the attacker were to log into a client account, a particular script would be ran, which grabbed data, or ran other scripts. In an even worse case, it might be a script that is stored for all users, and whenever any client were to log in this data-grabbing script was ran. Of course it isn’t all about data, and the script itself could be a lot more damaging , with the sole aim of crashing the web server.
- DOM-based XSS attacks: The script is executed in the browser, but completely on the client side and within the client’s DOM. This obviously makes it nearly impossible for a web server to log such an incident or to try and gather information on this type of attack; however most contemporary JS frameworks have measures put in place for this style of attack. The reason you would want to do this type of attack would be if inside the website itself there was data that sat outside of the client’s “bubble” but with a bit of tinkering you could get the website to reveal a more sensitive page, with more intriguing data.
XSS Scripting attacks are used for:
- Theft of authentication from a web application, and taking this token to log into other accounts.
- Session hijacking, jumping onto another client - server interaction and inserting requests
- Deploying hostile content. This would be the result of a P-XSS attack where the script is ran and for each client and it shows another input field , but with the attacker also relaying that info elsewhere…
- Changing user settings. Usually relies on either of the first two.
- Phishing, or the general stealing of information
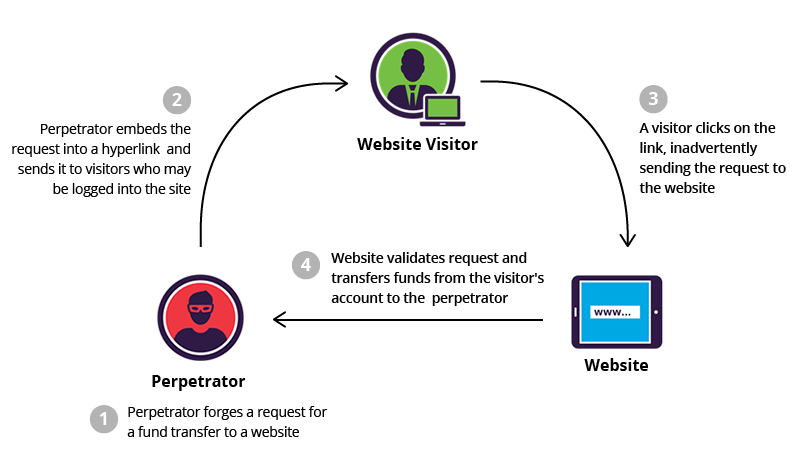
Cross-Site Request Forgery (XSRF) . This occurs when an attacker is able to utilise an authorised activity, like bill payment and it gets pushed outside of an authorised use case, i.e the billing page is sent to another user. The victim is an authenticated user, and so is the attacker but the trust is exploited by using a previous authentication request as the current one.
Now onto the epitome of network-based attacks , the Denial of Service (DoS), and Distributed Denial of Service (DDoS). The second a computer, be it a desktop or a server opens itself up to the wider world, as any normal website does, it becomes susceptible to this sort of attack. Pushing the idea of web traffic to the extreme, both attacks aim to overload the victim with packets. DoS attacks vary in style, and won’t always be network based. It may just be that an attacker utilises a known exploit in the client computer to deny authorised users access to an information system or the features of said system. A very simple, albeit very powerful form of DoS is where a script constantly opens programs and fills up the RAM of the computer and shuts it down, denying the user access to the entire computer. This idea can then be quieter, and work only for specific services etc. Onto the network side of things, one computer isn’t usually strong enough to send enough packets to crash a server, which is where DDoS comes in. Distributed comes from the fact that there are multiple systems , distributed amongst countries, and even continents all targeting a particular server. These computers are typically all previously exploited, and there resources geared towards packet spam. Networks of these compromised systems are called Zombie Networks. Another form of DoS is called an amplification attack, which doesn’t have the advantage of having a zombie network, but has the benefit of other computers on the network, and by pinging all of them (with the return address being the server or whatever) you then direct all their responses to the victim, and when it becomes too much to handle the crash is complete. Another similar idea is in the Smurf attack, which is where the attacker sends ICMP messages (with the return address from the victim) to all other clients on the network, and the victim is spammed with all the echo replies.
The two main types of spoofing are MAC address spoofing (for getting a malicious device to blend in on the network, disguised as just another one of their desktops) and IP spoofing , so as to make requests from computers which may have different access levels…
Now onto slightly more sophisticated attacks. Imagine a client communicating with a server, but unfortunately the entire thing is done over plain text, no encryption whatsoever. What if we were to plant ourselves between the client and server, so as to watch the traffic flow? Well this would be called a Man-In-The-Middle (MITM) attack and the captured traffic is relayed from the server , to us , and then to the client, who just assumes that communication is going fine as all packets are received. Replay attacks builds on this idea of capturing traffic, and replays them i.e sends the same packets, which hold the same tokens in an attempt to circumvent authentication mechanisms, such as capturing and reusing a client’s certificates / tokens. Pass the hash is an attack style where a packet is captured which holds the hash of a username and or password , which the system typically uses to pass onto the authentication mechanism. An attacker need not decrypt, he just passes this hash on within his own authentication attempt, the system might actually verify him/her and hence give them access. A variant of this MITM attacker is the Man-In-The-Browser attack, which is an installed piece of malware on a compromised system that logs user activity , i.e when they navigate to banking websites, do online shopping etc. The attacker could build up a detailed profile of the user, like which bank they go to , what are their common operations etc. The next stage would be to add overlays (well, underlays really) so that if a user wanted to pay a bill through the online banking platform, the browser could then , as the request is being processed, change the credentials and the attacker receives the money instead…
Now onto an attack that actually uses overlays. Clickjacking is where a user clicks on an ostensibly friendly image, not knowing that an attacker has wrapped the image in a <div> tag or some other wrapper which may redirect them or God knows what. It is usually used in conjunction with promotional posters, where there will be an advert, with an image the attacker wants the victim to click on, but instead of being redirected to the actual website they are redirected to a nefarious clone of the fashion site, where any money spent goes straight to the attacker. This leads me quite nicely into the next attack, which is URL Hijacking and Typosquatting. Oftentimes, an overlay will take a user to a site like gooogle.com which actually has 3 O’s, but if you’re drunk, or you don’t have your glasses then this might avert a user’s gaze and they use the site like normal, this is the art of the typosquatting attack. URL Hijacking is more general, and it is to do with moving the user to any evil site, not just the one mimicking an actual brand. As soon as you land there, then the attacker is able to execute the malicious payload on your system, and well , good luck to you…
Privilege escalation is the first step of many attacks, and it is to momentarily (or persistently through the root account) obtain root-level access.
ARP Poisoning. Now a little bit of background on how ARP works. Computers have their own ARP cache, which basically maps the MAC address of all the machines it knows and their IP addresses, this way it can construct packets that may need to know the IP of that device (office to office communication). Now if a computer didn’t know the recipient’s details, they would send out an ARP broadcast to the switch and that is relayed to every node, and hopefully the node which it applies to answers back and the client’s ARP table is updated. So then, a hacker may have breached a network, and it would be great if he could poison this cache so that the client would now send confidential packets to him (which he could relay) and he can do this by sending an ARP saying this particular IP address has changed MAC. So ARP poisoning has elements of MITM and Spoofing. There is also the ARP DoS attacks, where we broadcast the IP of the router as having changed MACs , to ours , and so all the traffic that would be going out of the network is now made internal and we can shut down the employees internet access immediately. Now in corporate environments such a switch-aroo is pretty much impossible nowadays , but hey , it’s on your exam! DNS Poisoning: Much like ARP Poisoning, this happens when an attacker manages to make unauthorised, incorrect modifications to a DNS table on the host system.
Domain Hijacking: This is the act of changing the registration of a domain name without the permission of the registrant (the person who registered with the registrar). The false domain is then spread throughout the DNS system when people start making requests.
Zero-day is a type of attack , which is functionally agnostic, it is just a type of exploit that the vendor of the operating system, or application , being targeted was unaware of this type of avenue of compromise.
Social Engineering attacks
Social engineering is an attack against a human (not physical , just trickery to get them to do something). It stems from the fact that the outer nodes of a corporation aim to be as helpful as possible, and we manipulate the corporation’s desire to do business, but on our terms.
Different types of social engineering:
- Phishing -> Sending clickable links , with fudged links to our “banking site”, to any email we can find
- Vishing -> Rare, but uses voice calls to spoof being someone else. Vishing is used to get personal information, PIN numbers, PII or even worse PHI.
- Spear Phishing -> Targeted emails to a specific customer, and we spoof being someone they know, so the chances of them clicking our link is much higher. Context is key.
- Whaling -> Spear phishing of a wealthy individual…
- Tailgating -> Literally following someone
- Third-party authorisation. Pretending to be someone else, and then the corporation believes us, and we get authorised for something…
- Help desk / tech support. Preying on the fact that a) they wish to be helpful and b) avoid confrontation. This is where we spoof our identity to either replace a credential that the authentic user has, like changing password or email , or we get the help desk person to execute a function that account has like making a transaction.
- Contractors and Outside parties. “Hello I’m the electrician ;)” . Famously contractors have planted logic bombs, they go and we get a repeat gig.
- Network-based , website-based attacks towards employees.
- Dumpster diving , searching through trash for old documents, tax receipts etc
- Shoulder surfing, like when someone enters their PIN at an ATM.
- Hoaxes
- Watering hole attack. Where we insert malware onto an employee portal, and they all come onto it, sign in and click on our bogus images or what have you.
- Impersonation. This is where we might call someone up pretending to be an employee - to get a workstation computer’s password changed. Or we could even dress up as a technician and try and make our way past reception.
- Principles. These are the psychological axioms with which a master social engineer will cycle between:
- Authority. Pretending to be a supervisor or the CEO of some company so that you get taken seriously.
- Intimidation. If you can pull of the threat, or if you’re physically quite scary then this could work…For example if you’re an insider and you process the payroll, you could threaten a new employee to do not snitch when you take your mandatory vacations otherwise you will break the system. Intimidation is boosted in strength when the victim is in a state of desperation.
- Building a sense of sociability and consensus like whatever you want them to do is normal - “Don’t worry I helped John with his account issues as well, let me take a look”. And boom malware is now planted. Let’s just go to my bugged rogueware site, ah there is the antivirus… Click click, yep you’re good to go!
- Scarcity. Giving some a limited time frame, limited resources. Utilise the fact a business is just starting and they need funds for example, this may get them to take a client which has other nefarious plans…
- Urgency. Couples well with scarcity , but along the lines of - “Come on we don’t have much time”!
- Familiarity. This is what spear phishing leverages , the someone we know aspect, which allows us to get past the first impression aspect.
- Trust. Not necessarily getting past the first impression stage, but getting us in the door and swaying them to cooperate. “I’m from the IT department let me have a look”.
Wireless attacks
A replay attack in the realm of wireless systems would be to run packet analysis on a client and server, regardless of whether or not the packet body is encrypted, but try resending these encrypted packets later in hopes of maybe logging into an employee portal.
Initialisation vectors are used as a randomisation element for each packet key, and is part of the key itself and used to encrypt the packet data, though the IV itself is sent in the clear over the wire. An attacker can then sniff the stream of packets, determine the sequence to which the IV is changing and then begin to insert their own.
Evil Twin and Rogue Access Points: Pretty much the same sort of idea here, but these two focus on setting up a “genuine” access point, which people can connect to and from there the attacker cans sniff packets and fingers crossed retrieve credentials. An evil twin is meant to replicate the actual network that serves customers. Here an attacker can send reconnect packets to everyone on the network to kick them off, and then they see the evil twin access point and connect, as it would have the same name. Often times the hacker’s access point has a stronger signal to entice people to select it, and device struggle to differentiate between the two. A rogue access point is just any hotspot that has been setup by the attacker, in wait for someone to connect and begin surfing…
Wireless Protected Setup. This is really just meant for home use, small-business use at a push. Essentially, the technology sits on a router, and it enables wireless devices to join without the need for a password. This works by having the router detect a new device, generating a unique 8-digit PIN which is then sent over to the client , albeit encrypted , and then the client can use this whenever they are in range. Now this isn’t the part which is too bad , the problem is that there are only so many PINs within a length of 8 , and so brute-forcing becomes especially attractive. The PIN method though isn’t the only WPS method that routers have been known to implement , NFC has been one way - where a device goes near the router and they sync up and exchange security info which around 30 seconds…
Bluejacking and Bluesnarfing. Bluejacking, much like clickjacking is the sending of malicious data to a device, though depending on the Bluetooth device itself there isn’t much for an attacker to glean, though they could just mess with it, change the volume, turn it off etc; Bluesnarfing is a bit more dangerous as it involves compromising the device, and pulling data from it. Again, depending on the device the files retrieved could mean the attacker completely mounts themselves on the device and it could be a trojan for going into other wireless networks. A good article on Bluesnarfing is here.
Radio Frequency Identification. RFID is what is used for most office buildings, users are given a card or a badge to gain entry into the facility. Attackers can spoof some RFID protection with their own cards, or they can copy the style of a card they managed to grab, putting the original back in place, and then using the copy to authorise an entry. Near-field communication. NFC is a set of wireless technologies that are used for short-range communications, like a phone and a card reader. It is an incredibly powerful device as the phone pretty much tunnels the reader into their financial institution. If you were to fiddle with these devices, and change the entity the reader would want money going to (to you), I’m sure you could go on that nice cruise after all! The difference between these two technologies is in their power: RFID is only meant to have a card-to-reader system, whereas NFC can be peer-to-peer as well as the standard card-to-reader. The uses of NFC will continue to rise whereas RFID has stagnated.
Disassociation. Attackers that are trying to sniff the connection to steal a password, but miss their opportunity have create a kind of workaround for this scenario. Disassociation kicks a device off of the wireless network , but since most devices are set to reconnect automatically, the attacker gains another opportunity to perform that sniffing.
Cryptographic attacks
Birthday attacks are quite interesting, and a little weird. As a general rule, given a group of 23 or more people ,the chance that two have the same birthday is greater than 50%. This same rule for passwords is then applied, and it’s estimated that two people in a corporation (if it is housing enough staff) will have the same password. Nowadays this is very rare, and there are variations, but nevertheless they are susceptible to a dictionary attack.
Known plain-text / known cipher-text attack. This is where an attacker manages to grab some of the cipher text alongside the plain text password, and can begin to reverse engineer the process of the encryption algorithm , using this fragment as an example mapping.
Password attacks
Poor password choices are the victim for all password based attacks, as there is no point really brute-forcing an administrator password; moreover we need to spread this idea of strong passwords right down to every employee, to give the sophistication of the admin and the ground level. There should be no relation between person and password i.e use of name, friend , address etc
The next step up is using hashes as a means of authentication, so if a password is entered it is converted into its “hashed” equivalent, which shouldn’t be able to be decrypted, and so brute forcing of hashes is all that’s done to get the actual password. Rainbow tables are collections of known hashes and what they map to, so an attacker could run the discovered hash against the rainbow table and see if this works out. To numb the effectiveness of rainbow tables, hashes have become longer due to a “primer” at the end , additional input that is added on by the hashing algorithm before encryption. This makes the hash longer, and it practically wipes out dictionary attacks, as it’s very difficult to comprehend how long, how intricate the added salt was and it doesn’t matter then if you do know everything about the person as that isn’t the only constituent of the password. The salt itself is not generated in relation to the input at all, otherwise the attacker could use the same hashing algorithm and generate the same salt… making it pointless, it’s just randomly generated , kept and then used as the salt for every password that is coming in to be hashed.
Collisions occur in the world of hashed passwords, due to the fact that hashing algorithm must return the same output for a given input, we can infer that a set of transformations are done that preserves the original password and scrambles it; However , due to the nature of the scrambling technique, it can occur that two different inputs produce the same output. This is a collision and can mean an attacker could use another word as an acceptable equivalent, and hence be logged in.
Dictionary attacks though are very strong outside of the salted hash world, and many times a server, portal or router password will not be backed by hashes, and so dictionary attacks become a valid means of exploitation. It is literally just a list of probable passwords, that you can add to if you pick up some extra info on the person / organisation. A good dictionary attack will include pwnme as well as pwnm3 as a password attempt, as people do this sort of thing to ostensibly improve security.
A brute force attack is much less sophisticated than a dictionary attack, and will use huge wordlists, not tailored like a dictionary attack, but just trying hundreds of thousands of attempts, but this obviously takes ages if the password is more than eight characters long. There are two levels of brute force, which vary depending on whether you do the attack online (like trying to log into another Linux user’s account) or if you are able to capture the password and then crack it in your own time, devoid of “maximum password retries” etc. This typically happens when the attacker manages to grab something like the /etc/shadow file and then they can begin to crack what maps to each user. This is obviously much faster since it doesn’t get impeded by the network latency and system response time (in the case of a busy web server).
A hybrid attack can be any combination of the above, in a systematic process of trying to acquire said password.
A downgrade is where an attacker purposefully interacts with a web server on an old version of HTTP, like 1.0, and because the web server wants to work with said client, they downgrade themselves and drop things like SSL/TLS connection to support this lower security option. An attacker could gear up this sort of connection between client and server, if permitted, and then run packet analysis on their conversation, as it is no longer an encrypted one; moreover it fractures the security postures of the website, and gives an attacker the chance to really understand its dynamics.
A replay attack is the reuse of a captured hash to hopefully be logged in. The difference between this attack and the wireless version, is that here we only make use of the captured hash (whether or not the hash itself is wrapped in encryption is irrelevant as we are hoping to mimic their conversation the client had, added encryption or not); whereas the wireless is to do with sending an entire packets and using the right one which contains all sensitive details to be once again handed over to the server (praying that they don’t use Kerberos - which gives a unique and temporary authenticated session).
And finally, the last thing to note would be weak cryptographic implementations , old algorithm versions etc.
1.3 Threat Actors
There are three things which really influence the category an actor is put into, knowledge of hacking information systems, the funding that this actor has , and their purpose.
Script kiddies are the lowest in all three, they have very little knowledge, so rely on the works and exploit scripts of others, they don’t have the funding to do things like crack large hashes and their purpose is just to make a quick buck for themselves, or a “name”. Depending on the surveys you see today of the actors responsible for breaches in governments , schools , shops etc , about 86-91% of those hacks were orchestrated by script kiddies.
Hacktivists are the next layer up with slightly more knowledge and funding, and with a purpose that is “a standard deviation outside of themselves”, usually for a cause or for an organisation. This is where hackers work together for a collective effort, and have the ability to write scripts that leverage a known vulnerability. This group of competent hackers makes up between 8-12% of all attacks seen today. As of the time of writing, the last known hacktivist effort was in taking down Police Departments across America , due to the death of George Floyd. These attacks were carried out by Anonymous.
The next, and far more powerful group , is the organised crime organisation. These gangsters have a lot more resources, and hence each hack comes with a lot more gusto and effort. More thought is put into each raid, and the tools created by these groups are extremely sophisticated, as they match their need to not get caught, with the funding necessary to provide this elusive features. The filthiest men make the cleanest escapes.
Now then, the most powerful tier in this hierarchy : the nation state. With a talent pool being the entire country and the government being able to add funding pretty much at will, they have the resources to seriously research and understand the innermost details about another countries' critical infrastructure. These are the elite, the ones who discover new vulnerabilities, write the scripts to bake the finding into a tool and launches that program for intelligence purposes. While they only represent about 1-2% of all attacks, they’re like a Tsunami : not often , but completely crushing. Nation states are also capable of very subtle attacks, like how China inserted spyware into their phone chips, so that people who bought them were logged by the government.
The last example I mentioned is an embodiment of the Advanced Persistent Threats (APTs) approach. They’re toolkits, hardware or software, with the intent of gaining access and maintaining a presence on a target system/network. The idea is that the attackers don’t just want the current information on a system, but also the updated information, the changes and the new data that floods in. This sort of access to such a wealth of intelligence is what nation states long for.
Insiders and Competitors
These are threat agents, which will be anywhere on this “scale” of threat actors. Insiders are definitely the most dangerous attackers possible, with unparalleled access, certainly versus any outsider, but they can gather unbelievable quantities of highly desirable information, and if they did wish to launch an attack, they have the power to insert physical media , like rubber duckies , into laptops, to hijack on-site servers, to change door codes etc. But don’t always think of insiders as master level hackers who suddenly choose to “flip” and break the company in two, sometimes these insiders may just be at the level of script kiddie, and most often times , breaches caused by insiders are accidental.
Competitors are less likely to be script kiddie level, usually they match an organised crime unit, as they are nevertheless organised. Companies have a dependency on their information systems, especially in this age, and anything a competitor is able to copy, steal , or disrupt would impact that corporation massively. “Competitors” may also just be propped up companies that other Nations will use to install malware on people’s phones, which is one conspiracy about TikTok.
Threat actor attributes
The internal versus the external. Internal threat actors have a distinct advantage over external actors in that they already have access to the network. Although they may be limited by user access provisioning, not only do they get a big reward for being a little creative (i.e stay at the office late and put a keylogger on the bosses' laptop) but they don’t have the extra step which external attackers do which is to break into the network.
Internal actors can immediately start working on step two of the attack, which is privilege escalation.
Level of sophistication. This is to do with the different skill levels an attacker may possess. The majority of attacks seen today exploit old vulnerabilities or simple methods, like default configurations, and abusing weak IoT devices; more sophisticated attackers use APTs and zero-day vulnerabilities, which involves having a broad, and deep understanding of the victim , but luckily for us they’re a small percentage.
Resources/Funding. Being on the defence is extremely costly, to pay people, to keep servers operational and to have surveillance on resources is expensive; likewise, attacks can be quite expensive : from the creation of new tools, to training hackers, to getting the bots necessary to perhaps DDoS a target. Naturally nation states and cyber crime organisations have an advantage over script kiddies.
Intent and motivation. Of course, each type of threat actor has different intents, as we know from the hacktivist community, with may just be data collection, or in the case of script kiddies, seeing their target computer crash. More sophisticated , intents , meaning those with a higher startup and preparation cost of delivery are the APTs that nation states and crime agencies wish to install on their victims.
APT (Advanced Persistent Threats) have three specific goals in mind :
- Avoid being detected
- Persist on the victim’s computer
- Take valuable data (copied without deleting on hard drive, but sometimes the drive gets overwritten as well)
Open Source Threat Intelligence
Open-source Threat Intelligence (OSTI) refers to intelligence gained from public sources and this type of data can be pulled from almost anywhere, due to the ease of dissemination. News articles, blogs, videos, twitter , government reports all assist in building a portfolio of the security landscape.
The main reason we want to use this data is that if we’re able to find it, well , so can the bad guys, and what’s worse is that this data is telling us about what tools hackers are using, only because hackers used those tools! They are way ahead of the pack, and so it is important that at least the reports come out as quickly as possible, if one is going to defend in a reactive manner.
Information Sharing and Analysis Organisations (ISAO) and Information Sharing Analysis Centres (ISAC) are both geared towards being massive repositories of information that corporations can subscribe to , so as to stay updated.
InfraGuard : A free service provided by the FBI on threat intelligence. However they are very slow , and the information they divulge isn’t fast enough to assist incident response teams.
1.4 Penetration Testing
Penetration testing , or pen testing , is performed to gauge an organisation’s security strength and to allow an “attacker” to peruse, attack and tamper with critical infrastructure. Now , obviously the agreement beforehand is extremely important, to tell the contractor, on-site employee etc what to touch and what not to touch… Otherwise there can be some real damage. The penetration tests are usually done by an outside agency that conducts a series of carefully crafted attacks against specified “units of infrastructure” that need testing, so that the organisation itself is aware of how they would actually defend in a real-world scenario. A penetration test must have some level of scope attached to it, as few companies want an attacker to try and pull up everything, as not everything needs testing. It might just be the bastion systems (public-facing) that need to be tested, and not the air-gapped wireless corporate networks. Scope could even be things like - “Only do wireless based attacks, try and send phishing emails to employees to see if our policies are being followed through” etc. Do they want us to do physical pen testing i.e break into the building?
From the tests holes are discovered and potential weaknesses are patched. In extreme cases, where employees are on something like Windows 7, then the agency would demand that the organisation goes through some serious updating…
The key difference between a penetration test and a vulnerability assessment is in their intrusive nature. Penetration testing is a depth test, just how badly could a single vulnerability damage an organisation, assessment is more of a sweeping action, a broad-brush stroke , which if it hits some jagged piece of configuration, or notices holes in security policies etc will notify the client of this.
Nothing really beats a good pen test, as the knowledge that flows is far more important, and already includes the information that a vulnerability assessment would bear, just for specific exploits, and giving better advice on how to patch each one.
Penetration Testing : Steps
You can think of anything and anyone as part of an organisation as part of its infrastructure. Any linkage suffices as an avenue for attack, no matter how contrived. In fact the contrived emails can be very potent, for example : You do a bit of googling and find that an organisation had an old domain registered with AWS but it has been cancelled as of this year. You send a spear phishing email , pretending to be the domain provider, saying that they had accidentally charged the account, though the account has been “recognised as closed”. Bonus points for showing the domain they had, the date etc. Make it look proper. The email wants the boss to log back on and claim “some apology coupons” for the wrongful charging etc. The boss does click the email and from there you can implant clickjacking overlays , whatever suits your fancy.
Step One : Reconnaissance
Reconnaissance comes in two major forms: passive and active.
Passive involves collecting information about a targeted system , network , person etc from public sources which are effectively untraceable to the actual consumer. This type of recon makes heavy use of Open Source Intelligence, the history and public documentation of the company - which is good for things at face-value and you can go onto an employee’s Facebook , Instagram and harvest all their posts to build a wordlist, but other than superficial things like this , which don’t make use of any real tools , you could just open your phone near their public offices and see what SSIDs come up (if any). Nothing in passive reconnaissance is illegal, and doesn’t need formal agreement or acknowledgement from the company itself.
Now active is where the fun starts. This is where we will make use of tools like nslookup , which still doesn’t need the permission of the company , nor is it illegal , but now we’re starting to be more intrusive - now we’re being logged by their servers and understanding their actual architecture. nmap is even more active, as we are making connections to their web servers, FTP servers etc. The water only gets murkier from here on, the line between what we’re freely allowed to do and what requires their permission.
Step Two : Initial Exploitation
After we have made extensive use of our reconnaissance resources, hopefully we have been able to identify some vulnerabilities present on the system. This stage focuses on utilising what we identified and seeing whether this vulnerability can actually be used, exploited, or maybe they patched it. With perseverance and a few late nights we have managed to exploit the target system with this vulnerability, and we’re in ! Now we can install our malware, maybe a rootkit , maybe ransomware if we’re cruel ? Gosh I can’t decide.
Step Three : Escalation of Privilege
Now we have access to one of the lower-level accounts, its time to break into the administrator access on this system. Now there are various techniques to scour the internals of the computer, for any avenues of privilege escalation, as we just need some program to run as root momentarily, we just need our use to click or run a single program with admin privileges. We could be really sneaky and put a RAT on the system, renaming it to some application that the user already has, and then when they click on it we run their app, but also ours and we’re running in an administrator program space - assuming the app needed admin privileges. But this is why the concept of least functionality and least privilege are crucial here, as it should make privilege escalation impossible without the higher-ups needing to know.
Step Four : Pivoting
Another we can do after getting into the system is to try and see who else is on the network, as this account is unlikely to have gold we need to look further into the department, onto computers on other office floors, other countries even. We can use the credentials on this computer to go up to FTP , LDAP servers and see what kind of resources we have access to. Whilst this is good, let’s see if we can gain access on another computer. Here is a great guide that highlights the power of Metasploit to pivot from one system to another.
Step Five : Persistence
Establishing a way to keep ourselves present on the system may be done quickly with a RAT, or we may need to slave away at finding some method of longevity - either through creating pseudo-accounts, or by connecting to some running process, and using our malware to create sessions with our computer each time it starts up. This second way is how persistence tends to be achieved, and a nice example of this can be seen here.
Penetration Testing Scopes
Gray box testing is where we are given some information, typically about a single server or a service running on a certain port , or it could mean an organisation shows us the “file” on a certain server, meaning things like its version, what patches it has , how many active connections it runs, whether it whitelists all the types of input it knows to be good, or whether it blacklists all known bad input (with then means we can try and slip through here…)
White box is exactly as you’d suspect, it’s where we have all the functionalities, quirks and data about a system at our fingertips. Remember , we don’t need to know everything about all the layers of an organisation’s infrastructure, but of the department they wanted us to test, we know everything about it. This sort of test is usually done when a new change is being put in place (like when all employees switch from Windows to Linux) and they want to see if they’re actually secure enough.
And lastly, black box testing is pretty much the antithesis to this. We’re basically given an IP address and off we go. This is where we pray passive reconnaissance comes in big time.
1.5 Vulnerability Scanning
First we are not working with an outside agency, as the assessment isn’t one that requires much skill like a pen test, we are just lightly going over what flaws are immediately present, which our system admins can do. Moreover once a vulnerability is found we don’t “see where it takes us”, but merely report it and hopefully find the patch for it. Vulnerability scanning should just identify the “lack of security controls/measures”, so we know where updates are necessary. The “broad-brushing” of this technique looks for well-known flaws within different infrastructure components, for example, if a department got a slew of new IoT devices, all with weak passwords like 12345678 then we could configure our vulnerability scanner to test these devices for misconfigurations etc. Vulnerability scanning is most often done outside of penetration testing, as admins will want to run routine checks on employee devices, to see if they are vulnerable at all , and to see if the patches installed on these systems - showing them to be up to date in the current climate.
A scanner can do any of these four things:
- Identify vulnerabilities, which is most commonly used for pen tests.
- Identify misconfigurations. So if we’re scanning a router, then we can see if there is any odd behaviour. For example, HTTP may be enabled by default or a junior admin accidentally turned it on thinking - “Well, we need HTTP somewhere right ?” and in doing so has meant I now can see the router login page which I can begin to brute-force. The same applies for leaving Telnet on a router, this would be a disaster as Telnet is a very weak protocol on its own .
- Identify lack of security controls. This is more to test company policy, so check if all the latest patches have been installed on a computer and to see if the latest antivirus has been installed. It differs from patch management, which is an updating tool used on the employee’s own computer and all this can do is verify that the patches from Microsoft or whoever have been installed, whereas a vulnerability scanner can be much more thorough and combine this with any security controls that were issued by the organisation themselves.
- Passively testing security controls. Whilst we want to test that security controls are in place, we don’t want to be so intrusive so as to break or slow the system, as we want the system itself to be available. Moreover, vulnerability scans may happen in the night time, when employees are heading home. Some of the weaknesses that the scanner picks up may be quite volatile, and pushing to see the computer’s response may be enough to tip it over - in the case of low-level exploits like kernel bugs.
Vulnerability Scanning methods
Intrusive Testing. Doesn’t go nearly as deep as penetration testing, as it is nowhere near as sophisticated or intricate, it just involves exercising any immediate vulnerabilities found on the target, and this could mean making changes to the target system (and hence cause harm). For example, you could configure the scanner to scour all the Windows 7 systems, and then execute the eternalblue vulnerability script we have written up that should do the work of exploiting that system.
A non-intrusive test is where the vulnerability scanner will never alter the target system with things like scripts or DoS attacks, it just checks standard things like open ports, is there an anonymous account open on the ftp server etc… So basically just automated active reconnaissance.
Now onto credential-based vulnerability scans. This type of scanning methods is primarily focused on accounts, not purely technical tests, and they sit on a slightly higher level - the application level. Any interface that probes for some form of authorisation will be tested. Now you might be thinking, but what is a non-credentialed vulnerability scan then? Well, if we take for example the network side of things, a non-credentialed would scan for open ports and anonymous ftp accounts, much like the non-intrusive, but with the added aspect that they can be intrusive and execute vulnerabilities that they find, just outside of the scope of crunching into an actual account. To provide some clarity here, all non-intrusive tests are non-credentialed , but not all non-credentialed tests are non-intrusive. Non-credentialed scans give us a good idea of what a particular aspect of the system is like, but will never go deeper, we can never truly understand the potential of what we find, without a good pen test.
Credentialed scans are pretty rare, as it means the vulnerability scanner is actually able to log into an account on the system… But if it does end up happening, then the scanner can obviously pick up lots of highly sensitive information, run enumeration checks and provide information on the application, or operating system. Due to the extensive checking of all applications and operating systems present in a given system unit, followed by the second-scan post log-in , this scan can take a very long time. This scan relies on the device having things like default credentials, or already being in possession of things like SSH keys - otherwise credentialed scans would be impossible without a brute-force.
Vulnerability scanning results
Now then, the scan’s all done and the report has been generated so it’s time to take a look at the results. A vulnerability scan is primarily done to establish a subsequent plan of action - i.e what needs patching, where are the critical issues, is the admin password in need of changing etc. Essentially , a system admin should ask themselves these two questions:
- What measures are taken when results are found? What I mean by this is , if we find a severe vulnerability do we have the appropriate policies in place to stop the attack from happening “in the real world”? What I mean by this is we may have found an employee computer with weak credentials, but if we have strong policies on network authentication, good NAC and NIPS - or even better - we have an air-gapped network, then the severity is largely reduced.
- How we do put controls in place to address vulnerabilities discovered during this scan?
False positives can occur in the report, when something is thought to be a vulnerability, but it is just a configuration we have, or the patch for a given vulnerability is in fact present; likewise, it could be that we have a false negative, which is when we hope to see a particular vulnerability to come up, but it doesn’t end up in the report. Understanding the why is just as important as the results that do end up making it.
1.6 Impact of Vulnerabilities
Vulnerabilities are the source of almost all security concerns, the exception probably being stuff like natural disasters, financial systems going bust, recessions etc. Vulnerabilities define the technical landscape pretty well, and the fewer manholes for attackers to slip into , the better. Each manhole is different though, and the Security+ exam will expect that you know the differences, the impact (damages) a certain vulnerability could do and how to mitigate it.
You can think of the open system, the endpoints being the fraying wires which an end user will make a connection to. The data that this endpoint sends , versus our own security configurations, and other users is the reasoning behind a huge number of vulnerabilities. The content of the data, the timing of many different endpoints to a single centre point (like clients and server) , the policies in place to blacklist or whitelist data all determine the damages.
By endpoints to a centre I can mean network nodes to a router, clients that take a slice of the server, programs that take up a slice of the RAM etc. The first vulnerability I will discuss are race conditions, which is where many threads within an asynchronous program will use the same resource, be it a variable, file, database etc , and if the ordering of the threads isn’t what matches the logic , it could cause a breakdown in the successive threads that want to use that resource. An analogy for this would be a squirrel trying to sink its teeth into a cashew nut, but then another squirrel jumps in and takes it! And the squirrel ends up biting its own hand : and in computer terms this would probably be enough to crash the program :/ The most common causes are with things like airline tickets , concert tickets etc where people click on them at the same time…
It may be that the entire output of a program is dependent on a specific sequence of events, and so threads that maybe are scheduled differently by the scheduling algorithm could cause a breakdown or crash. Locally this might just mean the crash of the program, but if threads were working on the kernel modules, then it could cause a system failure. Operating systems have to be multi-threaded, if you want a lot of services concurrently running, and sitting above that will be a lot of demanding programs etc. It isn’t really something we can just scrap and implement differently , as most of an OS is built on this, so we’ll have to patch it…
The first thing we can do is set up reference counters. These are structures in the kernel that flag when a resource is in use, so the first thread that makes a request will set this counter, and other threads that want to contact the resource may increment the flag , some reference counter modes come with memory barriers that specify space for each thread, but some might be just as simple (in the case of a variable) as a flag. See this to get the full low-down on reference counters.
Another thing we can do to stop race conditions is to simply lock the kernel down and have the resource become inaccessible whilst a thread is operating on it. The simplest type of lock is called a spinlock, which will keep trying to lock down a resource, and if it doesn’t manage it the first try, it will continue to do so, hence the spinning. Read and write locks use the spinlock functionality when trying to access a resource. Instead of shutting a resource down to a single thread, lots of threads can have a read lock, but if a thread wants to write to the resource, then no other process can have any lock, as they would be seeing the updated data structure.
Lastly, is thread synchronisation. This is where threads are organised into a queue by a scheduling algorithm and have their access to a shared system resource linearly, and they are prioritised based on the operation they have : read or write. The point is, you want to get the single write out of the way should a hundred read operations can happen concurrently, the only problem being that if a write operation keeps coming in , then it moves to the top of the pile and it can be “a while” before a read thread has the chance to access the resource. A great article on this is here:
System vulnerabilities
End of life systems are where the vendor no longer supports the device, software application etc at all. I mean, this is perfect if you’re inclined to take advantage of the old! Products like Windows XP are EOL products, and it’s rare that you will see businesses still have any copy of this rusty OS laying around, but if they do it’s pretty much certain that they will be compromised at this point. New vulnerabilities that we find targeting an EOL system will very rarely get patched, what normally happens is a big bank will find their Windows XP system has a severe vulnerability, and decry that Microsoft comes and fixes it, just this once! For smaller issues like buffer overflows these are ignored… If I were to get a new laptop, and put an old copy of Windows on it (god knows why) you may find that the OS struggles to support the device, and you present yourself with a unique vulnerability, in that you don’t know how to defend unless you’re attacked.
A lack of vendor support isn’t the same, as support isn’t entirely dropped, but you can’t expect much attention given to this product. In some cases, this may be because the company went out of business and now people who own the device or application now seek third-party patches, like you sometimes see forks on apps on GitHub. The impacts are the same as EOL, and you should seriously start to consider an alternative.
Embedded systems refer to those where a chip has been designed specifically for a certain system, like Tesla make their own chips for their cars, and they perform a specific function and are part of other systems i.e the engine. The main concern with these systems is that oftentimes they may not be prioritised in the overall patch management plan. In the unique case of Tesla, the embedded system is the only processing unit, and so it is highest in the patch management queue, but systems like food factories, or car assembly lines, then a certain machine may be left behind, and vulnerabilities are left behind - much to the joy of an attacker.
Improper Input and Error handling
I would say the number one cause of software vulnerabilities is improper input handling done by applications. Bar none, the amount of websites that are still vulnerable to an SQL injection attack is still too high, thousands of small business are starting to use things like Wix and Wordpress which makes the world slightly safer (though these frameworks then become targets…). Users can manipulate the regulations , which are usually too general, and not penetrative enough to match conniving agents who may insert SQL text, JavaScript code etc. The key to proper input sanitisation begins with escaping the string. What escaping means is that embedded strings are shown with a \" , so there is no ambiguity on how the interpreter should handle it. After this, the string should then be checked , preferably against a whitelist, though there are exceptions like emails . The regular expression for emails is so immensely complicated, but as long as it contains an @ and it’s escaped , the rest is fine.
Without proper input handling, you could find yourself in the following potholes:
- Buffer overflow attacks, where the input receives an absolutely massive string and crashes the backend.
- Cross-site Scripting (XSS) use of JavaScript code , which may be inserted through inputs and evaluated on the front or backend depending on where the script was entered, and how the system processes it.
- Cross-site Request Forgery (XSRF). This is where we forge a request, that we want an authenticate user to execute (through a link click or something) that then performs an action with their cookie , or token etc. This script can be put onto the backend and executed if it is included in a persistent XSS script, but it can be as simple as someone clicking on a URL , with the action embedded in the query-string of the URL and then the browser takes their cookie to the website for them and performs the action. Typically, the action would be something like changing a user’s email to our one and then calling for a password reset. The password reset is then sent to us, and we have control of the account. An article that explains this in depth can be seen here.
- Injection attacks like SQL injection involve putting an SQL command within a input field like “username” or “password” and when the database checks it with the backend, since the string is mangled with the SQL substring, which wasn’t escaped, then it gets read by the SQL interpreter which executes it.
Improper error handling is how we deal with, log and disclose errors.
Every system deals with errors at some point, smoothness is never certainty when we communicate with the outer, chaotic world and how we log data, and what the user sees may give an attacker a clue into the inner workings of the system.
One attack methodology is where an attacker will constantly supply error-inducing input, and get the system to fallback to exception handling. An example of this would be the number of tries in entering a password.
If we do show data to the user, just how technical is it? Normally this is all just sent to the server but using the JavaScript console baked into the browser, we can see all the currently registered objects and classes the site uses, and if the data has been stored, it is possible to access it.
Another good example would be if we’re trying to craft together an SQL statement, for our injection attack , but we don’t know the names of tables and things, so we send to the server a slightly altered request , from jumper to “jupmer” etc and then if the errors are logged at all, it may allow us to see the tables it searched through.
Effective error handling should be done on the backend, with the requests from the front coming through, and depending on the type of user (client, or admin) will determine how much we show; moreover, an Access Control List is important here to determine what sort of data is acceptable to communicate, and to whom.
Configuration vulnerabilities
Misconfiguration and weak configuration. Misconfiguration could mean a system admin has given too many privileges to a very low-levelled users and they have the ability to access files they shouldn’t; weak configuration is to do with things like passwords, where security policies are not in place to stop employees from having passwords like password which are terrible. Default configurations are passwords and security controls like usernames , PIN codes, that are set by the manufacturer, but are notoriously weak.
This sort of thing can happen to any device, any system and any business , so policies for this sort of thing must be one of the first (and most adhered to) policies. If you keep your default password on something like a router, you pretty much concede the entire network.
If you’re a system admin and it’s your duty to manage all the employee accounts : making sure they are in the right group for their department, that they have the right privileges etc. One common occurrence is to use Access Control Lists, which lists the privileges for groups and users, to tailor the access control on a per user basis… But this is pointless as hierarchies dictate roles , and not every employee has a unique position amongst everyone else, so it would save a bit of headache to use groups instead. Things can still balloon though, employees may move across departments and people may leave, and if they do somehow manage to end up in the wrong group they could be endowed with the powers of an admin , or root in linux.
If we can say for certain that all user accounts have the right permissions, then if an attacker were to compromise a user account, privilege escalation would be numbed. Organisations should make passwords stronger, secure root and check things like geographical login , standard hours of usage etc.
Memory and buffer vulnerabilities
When an input is accepted as part of a system, this is stored in the memory the program is allocated, and it’s retrieved when the system reaches for that address and pulls the data out, after which the variable is noted as being referenced, and it is garbage collected (removed to make way for other variables that may want that space). This space of memory where data resides is called a buffer, and hence when the allotted space is exceeded, this is called a buffer overflow.
Memory leaks are programming errors caused by a program not properly handling memory resources efficiently. In modern languages like Java which was made in 1995 , languages from that point have taken to using garbage collectors to manage variables and the like, so these memory leaks (where data is written to addresses outside the application buffer) don’t happen. When the program tries to request that block, the OS denies them, causing the system to hang, or worse, crash.
Integer Overflow is where a variable , meant to hold an integer or any numerical value, is given a number too large for it to hold. From this point on it is up to the program’s logic to see how it reacts to this value, and it may be so that such a wacky result in the program, dependent purely upon the language and compiler in use. In most programming languages, integer values are usually allocated a certain number of bits in memory. For example, space reserved for a 32-bit integer data type may store an unsigned integer between 0 and 4,294,967,295 or a signed integer between −2,147,483,648 and 2,147,483,647. In the case of signed integers, the most significant (first) bit usually signifies whether the integer is a positive value or a negative value.
However, what happens when you perform the calculation 4,294,967,295 + 1 and attempt to store the result that is greater than the maximum value for the integer type? It depends completely on the language and the compiler. And, unfortunately, most languages and most compilers raise no error at all and simply perform a modulo operation, wraparound, or truncation, or they have other undefined behaviour. For the above example, the result is most often 0. If the code has a test case for if x == 0 then this means we may see something different, possibly in our favour.
Likewise, the results can be even more unexpected for signed integers. When you go above the maximum value of the signed integer, the result usually becomes a negative number. For example, 2,147,483,647 +1 is usually −2,147,483,648. When you go below the minimum value (underflow), the result usually becomes a positive number. For example, −2,147,483,648 − 1 is usually 2,147,483,647. Now this has some serious problems, as the difference between positive and negative could mean the difference between a normal user and an admin, and if we can fiddle around with the app on our system with some luck we may be allowed to hop over.
It’s a nice little trick to see what happens , whenever a program asks you for numerical input.
Buffer overflows are a more general form of integer overflow, and happens with the resources allotted to an entire program. Extra characters get pumped into the memory addresses, and this could lead to other portions of the program being overwritten, and the affects of this are based on the significance of the overwritten code to running processes, maybe nothing happens, or the program completely crashes.
+-----------+
| |
| text | (fixed size)
| |
+-----------+
| |
| data | (fixed size)
| |
+-----------+
| stack | | growth
+-----------+ V
| |
| free |
| |
+-----------+ ^
| heap | | growth
+-----------+
This diagram here shows the memory segments that the OS allots to every program, with the heap being for dynamic data, which grows up as the program chugs along, and the stack is primarily for instructions. Notice how both grow towards each other? Well, with a buffer overflow, we can tinker with each side to swallow the other, more detail on exactly how for the more curious reader is here.
The worst case scenario would be that the attacker fills the program memory with their own script to execute, and that script is then given the space necessary to run. This would be really bad, especially if the program being tinkered with had root permissions… A demo of this can be seen on computerphile.
Pointer dereferencing is where we take a variable , which holds an address , a variable of this kind is called a pointer. By dereferencing we take what is within the address the pointer points to, which may be in some cases that doesn’t stand up to the input validation thresholds. If we can somehow change what is in that address space, then we would alter the logic of the program because of that pointer dereference. A buffer overflow can do this, and the script that runs could make tweaks to different memory locations, so when the application starts up again it would use the phoney data.
And lastly, Dynamic Link Library Injection. Libraries are essentially reusable units of code that serve an independent function, and have been battle tested by developers, and they’re essentially plugged into programs. There are two types of linking : static and dynamic. Static involves bundling the code with the program at compile time, so that we have one standalone executable which can be run anywhere , whenever we want , as all the code has now been packaged; dynamic on the other hand is where we leave the library linking until runtime, where the program has to be linked up with the library as it will be executed. A dynamic link library is something that Windows uses to insert functionality into executables, and if we are able to slip into this process, and insert our own malicious library, I’m sure you can see the opportunities here, especially since DLLs are often ran with administrator privileges.
Other vulnerabilities
Resource exhaustion. This occurs when a system does not have the amount of resources that it needs to continue operating. In some cases, if the resource exhaustion is suffered by a web server, it can mean the customer-facing operations may cease.
Untrained user. These are users who do not know how to manage the system properly. Which a) is extremely common b) are the targets of many social engineering attacks and plans c) create their own problems… The training and helping of these users begins with policies and procedures.
Vulnerable business processes go hand in hand with the one above. A common form of fraud is to send invoices to organisations for goods or services that they didn’t actually provide, but due to the fact that nobody is properly verifying the invoice, it goes along and gets paid for… Adding automation on top only cements this sloppiness.
Weak cipher suites and/or implementations. Using an outdated cipher suite, one that can easily be cracked is obviously a security concern; likewise, using the newest implementations is also risky, as there may be flaws and implementation vulnerabilities.
A good foundation of any security procedure is an acute awareness of the assets you have, what they require, and the state of that system. Management of each system is done in a way that best fits the corporation, but as long as things like network topologies, firewall configurations and patches are kept on top of, then things are off to a good start.
System sprawl is what happens when the systems expand over time and exceed documentation and knowledge of security professionals i.e a very messy room :/ Sometimes this sort of thing happens with virtual machines, and virtual machine sprawl is where an admin has lost track of all their instances and hence they fall behind, go unpatched and become exploitable. For an attacker, finding the difference between a virtual machine sprawl and a genuine goldmine is difficult.
Undocumented assets are systems not included in the documentation, and hence the intricate knowledge of these units isn’t there and they fall outside the scope of routine security checks.
Architecture / Design flaws. These are issues that result in vulnerabilities and increased risks based on the design and the choices made by those who influenced its architecture. A good example of this would be a flat network without segmentation , and no ACL’s on the router to compartmentalise things; moreover, if an attacker did crack that router, they know every single computer that the corporation has, extending the scope of attack massively. If you do end up making a mistake in your design, and only notice that years down the road, I’m afraid it’s gonna be a long hard road to sanity…
Improper Certificate and Key Management. Improper certificate and key management could lead to an improper or expired key being used to authenticate to the system. Proper certificate and key usage and management is the only mitigation for this vulnerability. For good key management an HSM is pretty nice as it is a physical device that stores , encrypts and decrypts these keys - and most of the time we have more than one web server that would need access to these keys, so there is no point securing them within a single server , like with a TPM or something.
New threats and zero days. Protection exists in the form of compensating controls here, which address future vulnerabilities indirectly.