CompTIA Security+ Chapter 2: Technologies and Tools
Table of contents
| Sections |
|---|
| 2.1 Installation and configuration of network security devices |
| 2.2 Assessing the Security Posture of an Organisation |
| 2.3 Troubleshooting Common Security Issues |
| 2.4 Given a scenario, analyse and interpret output from security technologies. |
| 2.5 Securely deploying mobile devices |
| 2.6 Implementing Secure Protocols |
2.1 Installation and configuration of network security devices
Alrighty, let this be the start of an incredibly thorough exploration on the technologies and tools you need to be aware of , not just for the Security+ exam, but if you want to secure your network, secure all the computers that you use everyday and how to communicate with all these other nodes safely. Essentially I want this guide to cover everything you need to know, but get to everything you need.
In this section we shall focus on network devices and network security, so let’s get started.
A Wireless Access Point (WAP) is a hardware networking device, that connects to a given router (the communicator to the outside world) and sends radio-based signals for wireless devices to connect to the WAP and so be granted access to the internet. WAPs , or more generally APs (as there are so few wired access points nowadays) , are governed by the Institute of Electrical and Electronics Engineers (IEEE) which set the standards for wireless communications, specifically their 802.11 set of standards pertaining to wireless communication: things like transmission speeds, maximum transmission range and such. The latest version , commercially named WiFi-6 , is the 802.11ax standard and governs 5 GHz Wireless communications for when 5G wired communication equipment becomes commonplace. This is it, as hardware develops and becomes more and more capable of sending more bits down the wire, we need our wireless hardware to catch up, and moreover we need our antennas to become more capable, as there is no point having all the kit, but when it comes down to it all our antenna can receive and issue is 500 KB of data…
Signal strength is determined by two things really: One’s own power - voltage , frequency, and the external environment which is the prevalence of other electrical equipment in the vicinity, affecting the performance of the WAP. Is it being blocked by some other wall, where is the WAP placed ? This will affect the usability of your WAP for sure.
When people want to connect to your WAP , or indeed straight to the router if it has that functionality supported (which most in the home do) then you will need to allow your WAP or wireless router to be identified - meaning you should be able to broadcast the name of said device to prospective users. The identifier itself is called the SSID (Service Set Identifier). When devices wish to connect to the wireless networks around them, they see these SSIDs , but the problem is they are passed to the client in plain-text, meaning attackers can just sniff around for all the available network names, kick people off (which is called a disassociation attack) then people reconnect to the network they believe to the genuine one, though an attacker has spoofed the name and now they act as the malicious MITM and relay their packets. How it gets to this point is due to a feature in WAPs called a beacon frame. This is the broadcasted packet that is sent out by WAPs to say to other devices - “Here I am” but obviously due to the insecure nature of this identifier anyone could pretend to be this WAP. This can be combatted by disabling the SSID broadcast but this isn’t a great security measure…
Bandwidths and Antenna Types
Tied directly to signal strength , there are many different bands that can be used in a wireless network and their respective bandwidths, but it all depends on what is easiest to implement in your office, cafe etc. There are two main types of antenna which is either sharp and precise like a laser, or general and sweeping like a broom. The first is what’s called a Yagi antenna , which specialises in signal strength and distance allowing the signal to travel on small amounts of power; the latter is called a Panel antenna and this one is great for corner offices , which speak with many wireless devices and they are all expected to be within a small radius, moreover along office floors we could have a wireless mesh topology that preserves a client’s signal strength regardless of where they are in the building. Antenna placement is so important, as we want to maximise coverage and minimise obstruction. We also don’t want the antenna reaching outside the area ! What if people didn’t have to pay for WiFi , or an attacker lurching in the bushes was able to send packets to my wireless router …
Below are all the main WiFi standards, which govern things like transmission strength , antenna placement , best use cases and best practices.
802.11ax (WiFi 6)
Branded as Wi-Fi 6, the 802.11ax standard went live in 2019 and will replace 802.11ac as the de-facto wireless standard. WiFi 6 maxes out at 10 Gbps, uses less power, is more reliable in congested environments, and supports better security.
802.11aj
Known as the China Millimetre Wave, this standard applies in China and is basically a re-branding of 802.11ad for use in certain areas of the world. The goal is to maintain backward compatibility with 802.11ad.
802.11ah
Approved in May 2017, this standard targets lower energy consumption and creates extended-range Wi-Fi networks that can go beyond the reach of a typical 2.4 GHz or 5 GHz networks. It is expected to compete with Bluetooth given its lower power needs.
802.11ad
Approved in December 2012, this standard is freakishly fast. However, the client device must be located within 11 feet of the access point.
802.11ac (WiFi 5)
The generation of WiFi that first signalled popular use, 802.11ac uses dual-band wireless technology, supporting simultaneous connections on both the 2.4 GHz and 5 GHz WiFi bands. 802.11ac offers backward compatibility to 802.11b/g/n and bandwidth rated up to 1300 Mbps on the 5 GHz band plus up to 450 Mbps on 2.4 GHz. Most home wireless routers are compliant with this standard.
- Pros of 802.11ac: Fastest maximum speed and best signal range; on par with standard wired connections
- Cons of 802.11ac: Most expensive to implement; performance improvements only noticeable in high-bandwidth applications
802.11ac is also referred to as WiFi 5.
802.11n
802.11n (also sometimes known as Wireless N) was designed to improve on 802.11g in the amount of bandwidth it supports, by using several wireless signals and antennas (called MIMO technology) instead of one. Industry standards groups ratified 802.11n in 2009 with specifications providing for up to 300 Mbps of network bandwidth. 802.11n also offers a somewhat better range over earlier WiFi standards due to its increased signal intensity, and it is backward-compatible with 802.11b/g gear.
Pros of 802.11n: Significant bandwidth improvement from previous standards; wide support across devices and network gear
Cons of 802.11n: More expensive to implement than 802.11g; use of multiple signals may interfere with nearby 802.11b/g based networks
802.11n is also referred to as WiFi 4.
802.11g
In 2002 and 2003, WLAN products supporting a newer standard called 802.11g emerged on the market. 802.11g attempts to combine the best of both 802.11a and 802.11b. 802.11g supports bandwidth up to 54 Mbps, and it uses the 2.4 GHz frequency for greater range. 802.11g is backward compatible with 802.11b, meaning that 802.11g access points will work with 802.11b wireless network adapters and vice versa.
- Pros of 802.11g: Supported by essentially all wireless devices and network equipment in use today; least expensive option
- Cons of 802.11g: Entire network slows to match any 802.11b devices on the network; slowest/oldest standard still in use
802.11g is also referred to as WiFi 3.
802.11a
While 802.11b was in development, IEEE created a second extension to the original 802.11 standard called 802.11a. Because 802.11b gained in popularity much faster than did 802.11a, some folks believe that 802.11a was created after 802.11b. In fact, 802.11a was created at the same time. Due to its higher cost, 802.11a is usually found on business networks whereas 802.11b better serves the home market.
802.11a supports bandwidth up to 54 Mbps and signals in a regulated frequency spectrum around 5 GHz. This higher frequency compared to 802.11b shortens the range of 802.11a networks. The higher frequency also means 802.11a signals have more difficulty penetrating walls and other obstructions.
Because 802.11a and 802.11b use different frequencies, the two technologies are incompatible with each other. Some vendors offer hybrid 802.11a/b network gear, but these products merely implement the two standards side by side (each connected device must use one or the other).
802.11a is also referred to as WiFi 2.
802.11b
IEEE expanded on the original 802.11 standard in July 1999, creating the 802.11b specification. 802.11b supports a theoretical speed up to 11 Mbps. A more realistic bandwidth of 5.9 Mbps (TCP) and 7.1 Mbps (UDP) should be expected.
802.11b uses the same unregulated radio signalling frequency (2.4 GHz) as the original 802.11 standard. Vendors often prefer using these frequencies to lower their production costs. Being unregulated, 802.11b gear can incur interference from microwave ovens, cordless phones, and other appliances using the same 2.4 GHz range. However, by installing 802.11b gear a reasonable distance from other appliances, interference can easily be avoided.
802.11b is also referred to as WiFi 1.
End note: 2.4 GHz for 802.11b/g/n and 5 GHz for a/n/ac/ax
Fat or Thin WAPs
Fat (or thick) WAPs can operate completely standalone . The implementation , configuration , authentication , encryption and updates are provided to just the one access point and they rarely require human interaction so they’re easy to manage and secure; whereas a thin access point needs admin guidance and inclusion, but often times there is another device which holds configuration details and operates as the controller. Such a schema like this may become more useful as the wireless environment grows and you need more power over your network. Such control gives better load balancing on devices connecting to the wireless network, and the management of this device is easily controlled and centralised.
Data Loss Prevention
Data Loss Prevention refers to the technologies put in place to prevent data loss. Simple enough really. They detect and hope to stop unauthorised transfers of data within the enterprise. This technology can be tuned to examine packets to detect specific data types, such as account numbers, social security numbers, and any other sensitive data.
USB Blocking is where we stop attackers from , in the event of gaining physical access, being able to steal that data - by introducing specific codes, encryption keys , or account details.
Email attachments are such a common threat, and something we can’t outrightly ban as we need attachments. One form of DLP attaches to the mail server and scans those communications that are similar to other network connections.
Cloud-based DLP . As more and more organisations move to the cloud, regardless of reason, DLP should still be employed. Many vendors now offer cloud-based DLP solutions. Leveraging cloud credentials to authenticate people wishing to access resources.
Network Access Control (NAC)
The process by which management connects each endpoint on a case-by-case basis. The two primary forms are:
- Network Access Protection (NAP). A Microsoft technology, used to control the connections at the computer host.
- Network Admission Control (NAC). A Cisco technology that determines whether an endpoint device is permitted admission onto the network.
NAC is useful for when we have a VPN server , and remote employees wish to gain access to the private network. It wouldn’t be good if that remote computer was stuffed with malware - itching to spread throughout the network - so we use NAC as a way of checking things like if the client has antivirus installed, what version is their OS etc. NACs fulfil whats called preadmission control as it runs through checks before granting admission. But there may be Post admission control which checks that the device’s compliance is ongoing whilst in the network.
There are two ways NAC can check the quality of a device, and that is with a dissolvable or a permanent agent. The use of a NAC requires an examination of a host before it is allowed to join the network. Agents are placed on a device at deployment to provide an integrity check in one of the following:
- Permanent agents: Can be deployed and stay on the device indefinitely. Obviously this makes it easier to run post admission control, but depending on whether the employee device is company owned or not will impact whether we can install this.
- Dissolvable agents: User clicks on a program at the employee portal and it runs diagnostics there and then - with their admin level permissions - to check registries etc.
Host health checks can be run before determining whether a device should be allowed to connect to the network. This could include verifying that the device has the latest patches , up-to-date antivirus etc. In some cases, a host can be added to an isolated network segment in order to pull necessary updates. In some cases, as an attacker manages to infect a system, then could run the updates themselves - avoiding the computer having to go into isolation and instead being allowed to connect to the corporate resources.
Agent versus Agent-less based solutions:
Agent-based solutions are where the agent resides on the host itself and awaits a connection attempt.
Agent-less based solutions are where code is stored on the network and deployed to the hosts as connection attempts are made.
Spam
Spam is undesired, potentially malicious and unsolicited email. It does present security issues depending on how well-crafted it is and what sorts of information they could pull from a given client, so it is critical to install some kind of spam filter. Filters are just software wrapped on top that tries its best identify and remove what it thinks to be spam mail , with some of the methods being:
- Blacklisting
- Content or keyword filtering
- Trusted servers
- Delay-based filtering
- PTR and reverse DNS checks
- Callback verification
- Statistical content filtering
- Rule-based filtering
- Egress filtering
- Hybrid filtering
Other network terms you need to be aware of…
Bridge. This acts as a connection between two or more network segments, nowadays this role is done primarily by the switch, but bridges used to be used for things like office floors and would work at the Link Layer - Layer 2 of the OSI model. Separating this traffic into multiple network segments enhances security , as this separation creates boundaries and more control over what set of computers has access to what kind(s) of resources.
SSL / TLS accelerators. Acts as a throughput between web servers and the broader internet. This device is used in solutions where SSL/TLS operations are done on a large scale to prevent bottlenecks in SSL/TLS encryption.
SSL Decryptors. Monitoring network traffic in an SSL/TLS environment presents a unique challenge as the data is encrypted , leaving security analysts without a method to examine the contents of the packets for suspicious activity. An SSL decryptor can be used to allow authorised security experts to decrypt this traffic for monitoring.
Media gateways. Usually part of a switch or firewall, a media gateway translates telecommunication protocols to other common networking protocols to allow smooth sending and receiving.
Hardware security modules. Network device that sits on the client computer and can manage, generate and store encryption keys to grant access to said computer. HSMs are designed to allow the use of cryptographic keys without exposing them to many attacks as they have built-in protection mechanisms. Also the decryption is done outside of the CPU itself, meaning an attacker that has invaded as deep as the cache cannot scour the system for any way to break into the firmware of this PC. HSMs also provide throughput efficiencies when compared to general-purpose machines.
Intrusion Detection Systems and Intrusion Prevention Systems
Think of a firewall as a bouncer at a club, they will most often just screen you , this being akin to checking IP address, requested port, requested service etc. Occasionally you will have a bouncer will which check you for knives and other weapons, which is comparable to an application firewall, which can scan the packet at the application layer, and check the body of this packet, which holds the HTTP packet or whatever. Now, an IDS/IPS in this sense may have the functionality of being at the door, but they also operate as the barmaid - as she can ask you questions, watch and log your activities.
Moreover an IDS/IPS is slightly more thorough and check the content of the packet , and their methods of alerting the host are slightly more sophisticated as they can drop, log , analyse , alert or even clean the packet itself to be granted entry; a firewall on the other hand is quite bipolar and if you have the right port, IP range, and protocol you will be allowed access - otherwise not.
The difference between an IDS and IPS is really just in the name …. an IDS will detect, log and alert security professionals to anything that violates the schema it was given, whereas an IPS will do this and more - it also bears functionality which could not only alert suspicious behaviours , an IPS can take steps to block a packet , without the need for operator intervention and stopping the attack in its tracks.
Intrusion detection and prevention typically work over a network, and are hence known as NIDS/NIPS - N for Network. They can also be installed onto host machines, and these are intuitively called HIDS/HIPS. The latter two detect unauthorised activity within the host, which will include the host sends and receives (as they must hit the system) , but they can also log key files, file structures, look at sections of cache and what scripts are running - essentially giving you fine-grained control of the host, so as to maintain stability.
Components of an IDS
First we need to actually have something which can collect data, normally this is called a sensor and it captures all the activities an IDS can examine. In NIDS the sensor acts as a sniffer , making copies of network traffic off of the network wire for further inspection. Sensor isn’t always the right term though, for example in a HIDS, it may just be that the system looks through audit logs and traffic logs for specific hosts, IPs, request times etc. An IDS can also be used for off-site storage - inspecting and monitoring data without causing performance issues across the network.
But how does an IDS actually check things? This is with the power of a signature database. It’s sort of like matching DNA to a criminal fingerprint, the IDS just takes snippets of data that are sensitive and run it through versus all the potentially dangerous variations it knows about (which would be a blacklisting configuration). The IDS could use the signatures as a whitelist, and anything that rests outside of the database for this particular packet, IP address or what have you should be alerted to the system admins. If a company is signed up with things like STIX , TAXII and CybOX then they can update their signature database more regularly.
Now the analysis engine is what combines the traffic from the sensor and the signatures from the database to arrive at an actual answer.
The user interface, whilst in seems obvious is part of the IDS/IPS nonetheless. The interface should show succinct reports , the latest audits done and it should be configurable so security engineers can put what they find most important on the foreground.
Categories of an IDS/IPS
I mentioned that an IDS/IPS can use signatures to blacklist or whitelist certain pieces of network traffic and this method of analysis is called signature-based. Now, being so reliant on signatures comes with two weaknesses : the first being that signatures must constantly be updated otherwise our blacklist is lost to time and becomes unhelpful, secondly as the number of signatures expands it becomes clunkier and oftentimes repetitive of more general patterns. It can also lead to false negatives / false positives.
Another way of analysing is to look at host behaviour or network behaviour - to acquire a “normal”. There should be a baseline of good behaviours and this can even be run down to specific users , so we would know when they went off tangent and hence alert them to system admins. Behaviours that do not comply get rejected, though there might be leeway, and with the all other methods they will need tuning every now and again. Behavioural may generate a lot of false-positives if it is too strict, as new behaviours (possibly new ways of working per project that the employee does) may be deemed as suspicious.
Heuristic is the middle ground between strict , logical signature-based analysis and statistical , wishy-washy behavioural systems as there is an algorithm that takes a look at different data repositories and tries to evaluate something as malicious or non-malicious using a combination of these methods. It aims to be more extendable and hopes that the engineers make frequent changes to it so that it can become more accurate as the business changes. The algorithm side is what distinguishes it the most from the other two, and it can become quite complex in some cases (with high-level accounts) and quite blunt with lower level accounts.
Anomalous analysis is similar to behaviour based IDSs , though there is a difference. Behaviour takes the same sort of approach as signature-based as it just looks over data and does the rudimentary comparisons - these sorts of IDSs just look for evidence of compromise without actually learning much about the system or developing its own profile for finding odd looking traffic or logs. So whilst anomaly-based IDSs have the same idea (which is flagging outside of a normal) this one will run through all the logs, databases and whatnot to build a baseline which it then checks new incoming data against.
More about their difference [here]([https://stackoverflow.com/questions/9228383/difference-between-anomaly-detection-and-behaviour-detection#:~:text=The%20two%20main%20types%20of,deviations%20on%20which%20it%20alerts.](https://stackoverflow.com/questions/9228383/difference-between-anomaly-detection-and-behaviour-detection#:~:text=The two main types of,deviations on which it alerts.))
All in all an IDS/IPS can use two different types of rules, to govern flow - either the simpler, stricter signature-based analysis or the more complex and involved algorithmic solution found in heuristic and anomaly-based systems.
With the data that an IDS/IPS generates we can create extensive data sets and this can be sent to an SIEM for further log analysis, scanning and overall big data analysis. I like the name Security Information and Event Management as information can only be classified as security information (information pertinent to organisational security) if we are indeed securing it, the more channels we open up the more secure we are theoretically, but due to the nature of the internet we sacrifice commercial viability for security. SIEM is a useful complement to an IDS/IPS as it includes standard session examinations between client and server, audits and past reports, vulnerability scanning etc.
NIDS/NIPS Methods
So there are two main methods that a NIDS/NIPS will implement and it all rests on whether or not we want to be active and on the wire, or inactive and working with stored data. The type of sensor we need to be on the wire is called an inline sensor which will monitor data as it comes into the network device, and will then invoke the analysis engine, which we would call an In-band system which will determine whether we should block or allow this traffic to pass through. In-band systems sit atop the shoulders of the inline sensor, and the two provide a good security advantage as we never allow the attacker a moment into the system; however, we pay the performance penalty of “live checking” and if there happens to be a fault with the NIDS/NIPS then it may say - “Look I can’t verify the stream so I’m just gonna block everything” . That’s no good ! In the end most corporations only have these sniffers on high value ports where we wouldn’t expect any high traffic volumes (not a commercial channel so we say). Firewalls will do the work of quickly blocking, we don’t need sophisticated stoppages as client profiles are too broad.
Now the opposite to this is the passive sensor, which will make an offline copy of the traffic. In the background it is then examined for suspicious activities by an out-of-band system , aptly named because it needs no wire and has no urgency , it is a reactionary toolkit that simply alerts if something malicious is sitting on the host. You can still have out-of-band prevention systems, as the connection between this client and the server may be ongoing, the NIPS can come in and close the connection down.
Firewalls
A firewall which can be hardware or software based aims to monitor and control traffic flow (incoming and outgoing) and determines whether or not - by some configuration whether or not to block specific traffic. It acts as the gatekeeper and is commonly used on the outskirts of business infrastructure as a defence to the wider world.
Firewalls can latch on to any number of servers, protocols , packets and such - Here are a handful of the different places we could use a firewall :
- Basic packet filtering. The most common firewall technique is simple packet filtering , which involves looking at the information contained just within the packet headers - ports , protocols , source and destination addresses - and checks against the firewall rules to make that determination. I think of it sort of like “broad-brush parenting”, as the parent looks to see if the child (the host on the internal network) should make friends with this computer and screens them in a generic fashion i.e do they swear , are they from a rough neighbourhood ? That sort of thing. Now it might well be that the firewall checks are unfair, and it truly comes down to the content, but most networks would find serious performance degradation if they started thorough inspections on every packet. Just check that the client is starting the sessions, and that the sessions themselves are from trusted sources. When we visit websites though, it may not be enough to vouch solely for the right IP , and for websites to bear certificates is another level of showing authenticity.
- Stateful packet filtering. Now this goes hand in hand with checking the packet, but with this type of inspection we check the connection. So the questions a stateful firewall might are : Is this a new connection, or already existing one ? What are the parameters of this connection i.e TTL of packets, what version etc. Did it originate from the internal network and if so the basic packet filtering would come in and check the IP is a whitelisted address. Another technique that stateful firewalls do to manage connections is to close all ports, and only open them up when they are needed, this prevents attackers from sniffing around any open ports and sending malicious packets - commonly known as port scanning.
- Network Address Translation. This happens in most network topologies that have a competent router, where the NAT device (the router) will bear a public IP address for all the client devices, with their own private IP address to make requests through. Routers can setup a software firewall module which will usually do the job of utilising this public IP in its traffic checks, seeing if packets are genuinely in talks with private devices - and if the communication was started by the private device itself, otherwise they are just rejected. Here is a great article talking about NAT firewalls.
- ACLs. These are some of the rules that a firewall , stateful or packet-based, may refer to. Lists of users, devices address and their associated permissions. Typical firewall rules outside of this will do what’s called an implicit deny, which basically means - “Hey to everyone that doesn’t fit our criteria, it isn’t because we targeted you out, it’s just not within own requirements…” , but an ACL will be a lot more strict and explicitly define the things a user can and cannot do , where they can and cannot go. So when some sites make a request but the IP is a known bad IP then it is rejected immediately. ACLs as we know from other sections, and in future sections aren’t just for firewalls to refer to, active directory servers like LDAP , FTP and such will make use of these and they can be used all the way down to the physical level - where bouncers at nightclubs have a whitelist of “VIPs” and then there is the list of known baddies in the area.
- Application layer proxies. Contrary to network-based protocols, that only look at the source and destination addresses , ports and protocols used application-based firewalls have the ability to go deeper and analyse the traffic itself , looking at URLs, cookies and such. The obvious drawback though is performance as the firewall spends a lot longer per packet , but for things like employee portals this is so important to properly verify. A web-application firewall (WAF) differs slightly from a NIDS/NIPS as it has a much greater awareness of what constitutes malicious communication, right down to the JavaScript - to check whether it is a known XSS attack. This differs from the signature based systems as they just look for known evils, but really the tricks could be a lot more complicated and hidden in things like cookies. WAFs are the powerhouse, though you do get package solutions, where the hardware firewall encompasses both systems.
Proxies and Load Balancers
Proxies are essentially a “friendly middle man”, that are used by organisations, at home and in offices to regulate client (and sometimes server) communications. So, let’s say you have an employee wanting to go onto cnn.com they make the request over the corporate WiFi, this first gets routed to the proxy server, who takes a peek at the request and checks whether the website is in the whitelist. In the case of a forward proxy, which resides on the configuration of the browser usually , this will be standard protocol. The proxy uses its own IP to communicate with the server, saving the private client IP address and then relaying the data back.
A transparent proxy pretty much operates in the same way - checking packets and using its own IP for safety, but the packet doesn’t stop when it hits the proxy , it gets redirected to the appropriate source and the packet itself isn’t modified. It dodges local firewalls , like how some Chinese internet users will use this sort of proxy just to bypass the first great wall and then they are free. But most people in this category just use an encrypted channel + a foreign web server (proper VPN) and this is much better.
The difference between a forward proxy and a transparent proxy is that the latter can be engineered into a network without any modification needed on the client computer (to wire it in the browser), nor is the packet’s journey stopping at the transparent proxy, it just gets the green light to be forwarded up and out. Now this isn’t entirely true, as a proxy can sit as the gateway of a network (router pushes them to the proxy instead of working with the packets immediately), and this is done so that - in the case of a Starbucks cafe - the client logs in and the proxy sees they aren’t authenticated, so they get redirected to the cafe login page and once successfully integrated they get redirected again to a “thank you” page, and they can browse like normal. A forwarding proxy wouldn’t be as seamless, and the configurations for someone to start browsing would have to be done explicitly, meaning the browser and network configurations would get the router IP and things instilled this way. Moreover this is why a forward proxy is also called an explicit proxy.
Now that I have so wonderfully illustrated how proxies work :sweat_smile: we can look at reverse proxies. This is where instead of planting a server in front of clients, we plant one in front of servers. The reasoning for this could be for traffic filtering, as a light skimming. An example would be for US web servers filtering EU requests, as they might not be GDPR ready, and this is a quick way of solving that issue. The reverse proxy could also sit and do SSL/TLS decryption before handing the packet to the web server. It just means that the web server doesn’t have to work with sensitive data like IP addresses, and the requests that do come in can be tuned. The best use of a reverse proxy is a nice segue into our next topic which is load balancing. Load balancing is pretty self-explanatory and what the proxy allows us to do is control the flow of requests, and if need be it can push packets to different webservers, thus making the whole process more efficient.
There are many different ways a person can make use of a proxy, and there are many different ways we can build a forward , transparent or reverse proxy. Some of the many types include:
- Application proxies. These sit in front of FTP, HTTP(S), SMTP servers and can do basic authentication checks that a server may not be able / wanting to do. What I mean by this is that the client may hope to make a straightforward request to the server , the standard way, but maybe the packet isn’t authenticated, and so will need some kind of access token. An application proxy can also cache all those that do make requests, and then use this latter for logging purposes. The proxy itself can be transparent as there is no knowledge - to the client - that this setup exists.
- Multipurpose proxies. Proxies can be configured to either insert headers into packets, log packet data, authenticate packets, redirect packets - the list goes on. And such proxy servers that the company owns can be shifted to sit in front of other servers (simply by changing the configuration of the proxy to relay to another server).
- Anonymising proxies. Makes a user’s web browsing experience “anonymous” to a certain degree, as the proxy IP is now being used. This would be akin to a forwarding proxy, as we configure the proxy on our computer, and they go and grab the resources for us.
- Caching proxy. Keeps local copies of common resources that people make requests to, like photos, files and webpages.
- Content-filtering proxy. Examines each request to check if the resource is whitelisted and may compare it against things like an AUP : “All employees cannot use their workstations to watch **** “. Used mainly in corporate environments to create a wall around what an employee should be able to view.
- Open proxy. Anonymises web traffic but the proxy itself is available for anyone to tunnel through.
- Web proxy. Specialised caching proxy, designed to handle web traffic and maintain a cache for regular websites. Now you might think that websites are updating all the time, but some only change if they release a new article or something, and so the proxy can get updated at this time and then users can view what would be the most up to date version, just quicker.
Load balancing
Now to go into a bit more detail about load balancing. If we can somehow manage to distribute traffic across critical servers, then it reduces the workload, improves the longevity of the hardware itself and creates faster response times. If webservers that have this load balanced architecture are employed, what would really help is if they were stateless, or where the state would never have to be manage by any specific server. What I mean is there shouldn’t be such a level of uniqueness and any webservers should be able to talk to that client, and the requests they send can both be authenticated properly, or run through the pipeline.
Proper organisation of resources is called scheduling. Scheduling is where we employ an algorithm which should fit the style of traffic the best i.e is it few users making many requests, for many users making a small number of requests. While the packet count is the same , the number of entities is different, and for scheduling algorithms like round robin, this may mean that it would be stuck on one user for such a long time that no other users would ever get anything processed. Another way would be to just to bundle packets into groups, to do an entire sessions worth, and then switch over.
There is also affinity-based scheduling which means for each host, they should be able to stay connected with a particular resource for an entire session, either by giving them a token or cookie, or with some lower-level TCP trickery.
Having a single load balancer watching over all of our servers might not be a good idea , as the load balancer itself may get overworked, break etc. We could get a backup load balancer sitting around as like an auxiliary, so if the first one fails we can use the replacement. This scheme is called an Active-Passive load balancing scheme. Active-Active on the other hand would be to utilise all the load balancers we have , though some companies will still preserve one for backups.
A much more in-depth guide to load balancing can be seen here:
Virtual IPs. When accessing a web server, that specific IP address may just belong to the router, or to the reverse proxy and all the servers sitting behind that domain will operate with the same virtual IP, obviously bearing their own distinct addresses, but sending responses through this IP address. Load balancers keep this VIP with them at all times, and whatever servers we may add they just need to respond with this IP. All load balancers need this IP as the connections might break if we try to push work around to different servers. The servers themselves are called virtual servers, because they are thought to be just layers underneath the physical load balancer server.
Router and Switch security
A router is probably the most important, and the most complicated piece of tech that sits in anyone’s network. They have to work with all the client computers, find out the best path for each user to take, they have to run Network Address Translation - wiring up the private IP to the router’s public one and keeping track of that, and they have to be able to authenticate new users properly. This last bit is what most network communications then base themselves off of, as we also want to be in a position where we can check the traffic itself, so the packets coming towards our clients isn’t malicious.
Routers make use of an Access Control List to determine whether source addresses are actually safe, or indeed known bad. They also work when someone wants to make a request to the router, they can refer to their list of known devices and if this requester falls outside the list their request is chucked. An ACL is bound to get chunkier though and the actual time a router spends sending packets off gets slower. The solution to this would be to only have a chunky bastion device, and any internal routers or switches shouldn’t have to worry about internal traffic.
Antispoofing is where the router utilises ACL rules to drop packets that may be coming from bots, their source addresses should be seen as a known bad and their request packets should be rejected. Although, the router can spend all its time rejecting the bot’s packets and nevertheless be frozen out. A hardware load balancer of sorts is the answer.
Switches
The backbone of a LAN is the switch, which specialises in node to node communication within a network, and operates at the level 2 layer of the OSI - the link layer. Physical cabling and MAC addresses are what the switch really needs, no IP addresses just yet, just Ethernet frames. Switches have many ports which a client can connect to, and these are the three main methods of port connection (and port security) you need to know for the exam:
- Static learning. This is where specific MAC address are assigned specific ports. Which is most useful when you have fixed, dedicated hardware.
- Dynamic learning. The switch learns which MAC addresses should be used as they connect, as they may be pulled out and then reconnected , so it’s just a means of keeping track of all internal devices.
- Sticky learning is much like dynamic, in that it can even allot multiple devices to a single port, but the real benefit is that the table persists in memory even if it is turned off or reset. This prevents simple attacks like forced power cycling from wiping the table.
Switches, due to their layer 2 nature (although there are layer 3 switches) suffer from something called “looping”. Know this usually arises when a network with two switches receives a broadcast packet, the first switch will relay this to all neighbouring devices, all devices that are connected, and then the broadcast packet is sent to the neighbouring switch. Problem is that now this switch relays it to everyone on its network, including the last switch, receiving yet another broadcast packet and the loop goes on ad infinitum. In this case there is no breakpoint in the network, there is no way to cure our looping ways, we need to be able to either kill or drop packets. One way of doing this is to utilise the Open Shortest Path First (OSPF) algorithm which essentially enforces a point-to-point topology that prevents looping, a separation if you will.
Spanning Tree Protocol is the other method and it acts by trimming connections that are not part of the spanning tree, connecting all nodes. Nodes that are also switches are treated differently as the direct links between them are considered redundant (now a virtual link , a channel we would only use as a fallback) , and when the root linkage breaks then we still wouldn’t get loops as that one broke. It just minimises the ways in switches can communicate. Best illustrated in this explanatory piece.
There is another type of attack that will invariably get tried on switches at some point, and that is the MAC flood attack. What happens is an attacker will send a large number of frames , each with different MAC addresses, and the internal switch table will try its best to save every address so that it will be recognised with that port in the future. The only problem is the switch will keep trying to save everything, which will cause it to run out of memory. When this happens a switch will drop to a fail-state and start acting like a hub, where it will flood every port with every packet it receives… All it takes is an attacker sticking a protocol analyser down and watching all the ports coming their way … Many switches nowadays come with a flood guard to protect against this, and will allot a specific number of address to each port, based on:
addresses per port = total address space/number of ports
If the switch detects the attempt at someone trying to be associated with a particular port, then they will be blocked and an alert will be raised. The flood guard will typically send an SNMP trap and may block the report until an admin intervenes.
MAC Filtering is another concept which is stringent on communications, but switches utilise this technique in the same way a router does an ACL. This provides pretty minimal security though, as the attacker will just spoof the address once he/she knows of the accepted range, or accepted list of MAC addresses. On a wireless network this problem is exacerbated by the fact that MAC addresses are often times transmitted in plain text , making it easier to find a good mask to hide behind.
Security Information and Event Management (SIEM)
This system is meant to be a centralised logging process, which takes the reports of all sorts of things like routers, antivirus, firewalls, proxies , IPS/IDS and the list goes on. This tool combines the monitoring , analysis and notification powers of a Security Event Management system (SEM) and the storage , report generating ability of a Security Information Management System (SIM).
SIEMs become more and more useful the more the business grows, as we would have too many individual sources of information to keep track, but if we wire them up to a centralised point, it becomes easier to comb through and manage. SIEMs can be used in tandem with scripts, so when alerts are given to admins, the SIEM could execute the relevant script. Often times triggers will be pulled when a particular action occurs - say for example when an attacker keeps trying to enter password for the SSH account of a particular computer , as the login attempts have been reached then the SIEM may execute a script that turns that closes the port on that computer.
- Aggregation refers to combining several dissimilar items into a single item. Now each source may have their quirks on how they stored the data on their own system, but the SIEM will be able to work and translate a wide variety of report data.
- Correlation engine. A correlation engine is a software component used to collect and analyse event log data from various systems within the network. It typically aggregates the data looking for common attributes. When it finds a particular pattern of behaviour it may raise an alert.
- Automated alerting. A SIEM will come with some predefined alerts, agnostic to anything it finds in accumulated reports - but instead whilst monitoring. If it sees that someone ran a port scanner on our web server it may issue an automatic alert to admins.
- Automated triggers. See paragraph above.
- Time synchronisation. All servers sending data to the SIEM need to have an accurate time, it doesn’t matter that they are in different time-zones, but when we translate their times to something like GMT it should all end up the same. This will help when we do things like auditing or incident response as we need coherent logs to build up a sense of time and space around the period we’re investigating.
- Event deduplication. Whilst we get a lot of gems in the logs, there are a lot of repeat entries and boring entries… Some of the logs on a NIDS and Firewall will be the same so there is no point in storing more than one copy.
- Logs / Write One Ready Many (WORM). A SIEMs logs will typically immutable, so nobody else can make modifications to those logs
2.2 Assessing the Security Posture of an Organisation
In this section we will be using some command line tools, to check the security controls that have been instilled into our network, on our DNS servers, on our own client machines and so on. The goal is to see whether such simple tools - which script kiddies have access to and know how to use - would be able to glean important information from our organisational infrastructure.
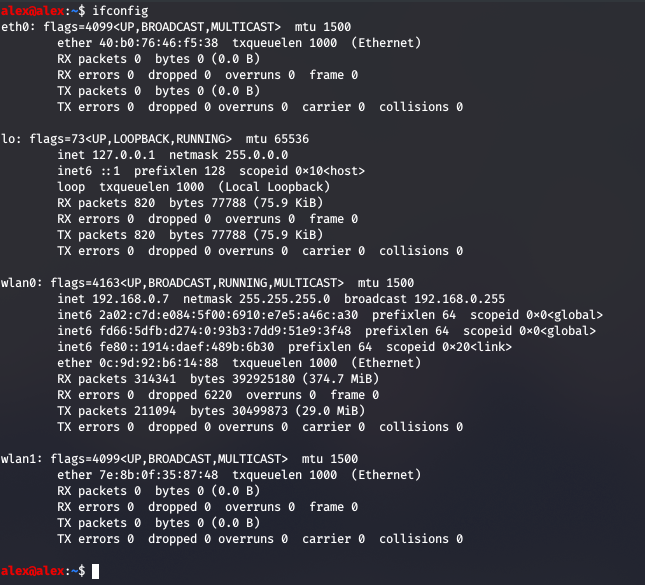
ifconfig and ipconfig
The first tool will be the simple ifconfig , or if you’re on Windows ipconfig which will tell you the IP address of the localhost, and the interfaces available (like eth0, wlan0 etc) and it gives you the machine’s MAC address. There are some differences in philosophy between the two tools, as the Windows version does not allow you to make actual network configuration changes through the tool itself, it is used more as a tool to retrieve network configurations; with this in mind, it makes sense to put the ifconfig tool behind a layer of security, like making the user enter their password to sudo or maybe behind the root password if there is a different password for root set on the machine.
These commands can also establish an ARP on the different interfaces. So , if the client was using eth0 to communicate with other wired clients or servers, then ARP can be setup - which basically just means Ethernet frames now include an ARP request , which goes to the switch and then that gets redirected to the right client.
We can turn interfaces on and off:
;; to turn it on
ifconfig eth0 up
;; and to turn it off
ifconfig eth0 down
;; enabling or disabling promiscuous mode
ifconfig eth0 promisc
ping
This is another tool mainly used for network troubleshooting, and to test if remote devices are reachable. The ping command will send ICMP (Internet Control Message Protocol) Echo requests. ICMP is used mostly by routers to send error messages, or simple bits of information to a client when an IP request has failed for whatever reason - maybe the IP address isn’t active, it couldn’t find a route, or the service wasn’t available.
Moreover, we can use the framework that the ICMP standards give us to use ping as a layer above, and we can choose how many packets we want to try and send, of what size , and see if we manage to get anything back. If there aren’t any problems the packets we issue will be received and confirmation will be given to us.
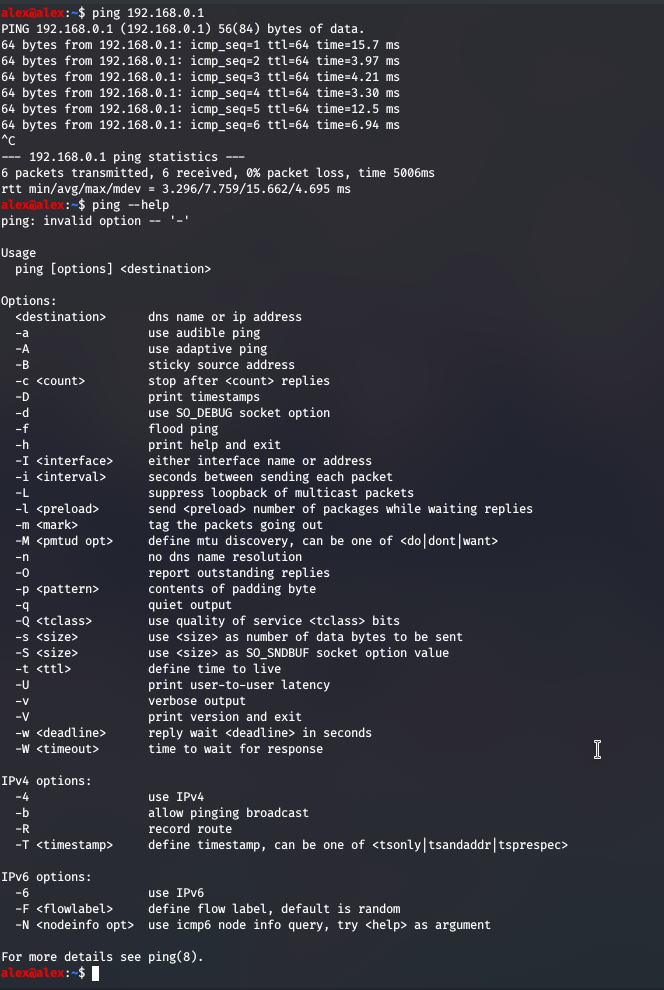
So I ran the first command just to see if I was connected to my router, and indeed I am , but a little improvement I would make is
ping 192.168.0.1 -c 4
;; just to send four packets...
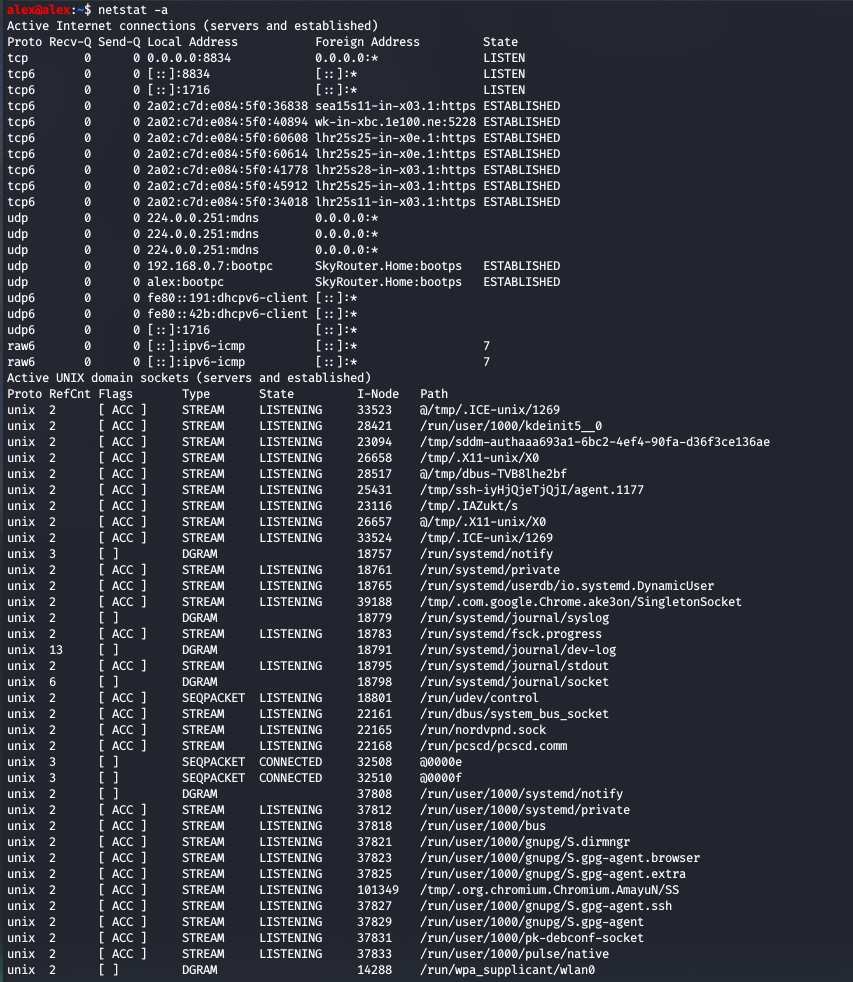
netstat
The netstat command gives you the network statistics of each connection type (TCP, UDP) that are currently established on a system
netstat -a lists all active connections
netstat -at lists alL active TCP connections
netstat -an lists all active UDP connections
traceroute
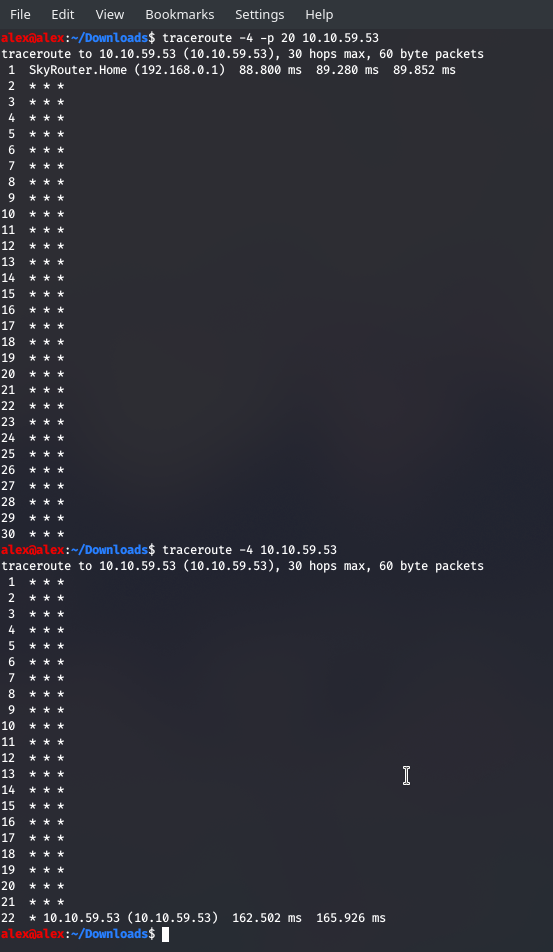
Now this command is super powerful, as it effectively takes the power of ping, which does ICMP echo requests for a single device (to check whether that single machine is available), but what if that machine were many “hops” away from you? What if you had to go from one router to the next until you finally crossed into their network and tested your connection to this client , well this is where traceroute comes in and it sends back ICMP echo responses to our machine after each hop. From an attacker’s perspective this gives us a slew of information - like can we actually be allowed into the network in the first place? Is there a firewall at a certain point that prevents us from getting to the client, what are the router IPs themselves as we make the journey?
traceroute is sort of like a tourist travelling across Europe and sending postcards at each point in their journey, allowing us to build a catalogue of information. Now rather depressingly, if you do try this in the real world, you might struggle to garner such information as routers are blocking ICMP requests, which is why in my example below we didn’t really get anything in the midst of our journey.
dig and nslookup
These are tools both used to query DNS servers, to see what kind of records each organisation has, what kind of certificates, what are the IP addresses of the mail servers etc. The difference is that nslookup is quite an old tool, with fewer options than dig, though it is great for beginners - to start them snooping around - and then learn dig as things get more thorough. dig can read requests from files and do batch running as well, and the example below is where we are searching for some PTR records , which are the inverse of A records (domain -> IP address). Here we can see that for this IP address we get back the domain infosecinstitute.com.

arp - Address Resolution Protocol
Devices sometimes need to send traffic using the MAC or layer 2 address of the destination host. ARP handles this by creating a table of those machines that it has communication with on the system - this table is called the ARP cache. This keeps all known IP addresses and their MAC addresses, so when we have an incoming packet from our router (a response from some server - the packet itself containing our MAC address), then the switch is then handed this packet, runs the MAC through
Administrators can use the arp command to see what their machine has (what their kernel logs) and generates their local ARP cache. We can then compare ARP tables and admins can see if someone is spoofing their IP as we will see the different MAC ,compare to our actual , physical neighbouring client office computer. Worst case scenario would be the ARP table being poisoned, tweaked essentially,
arp -a
;; show all entries in table
arp -d <IP>
;; removes the IP
Try not to get too confused with ARP tables, which reside on the client device - and keep a record of other clients on the network - and the Content Addressable Memory (CAM) tables which switches keep and they keep track of every device which is connected to them.
tcpdump
With this we can capture and analyse network packets that come into our device, and what sorts of communications our computer is currently having. We can save this stream of TCP data into a .pcap file. We can then use tools like Wireshark which will sniff around and scour the file for anything juicy.
So I just typed
sudo tcpdump
Waiting to see what cropped up, and I got some interesting little bits:
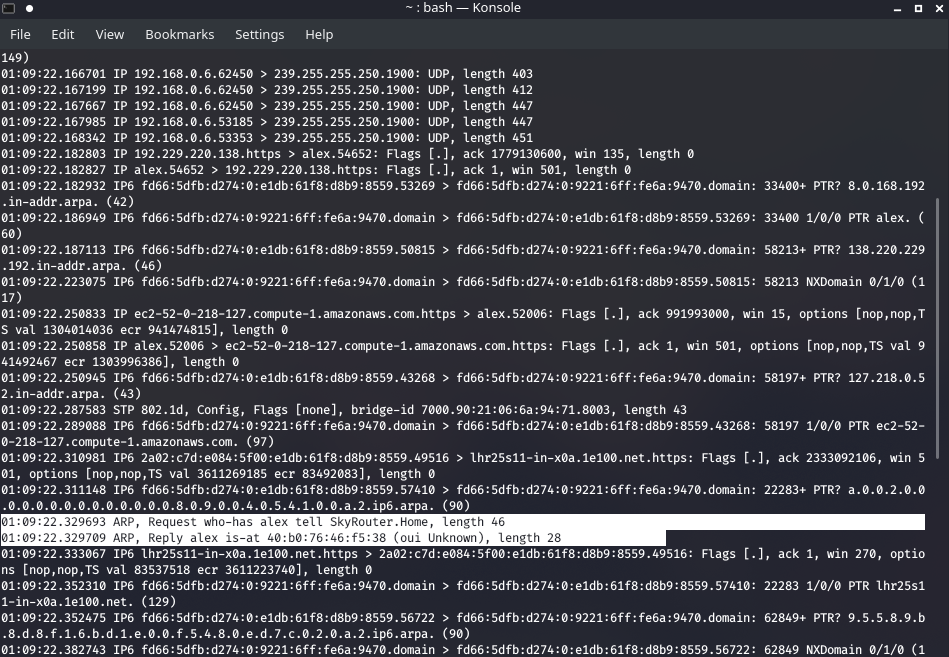
Security Tools
There are two main types of tools
- Active : Where we send traffic to the target device to gain some information about that device, akin to an
nmapaggressive scan. - Passive tools. Where we listen and see if any broadcasted traffic comes our way, so we can learn about what systems are on the network, their IPs and such.
Protocol Analyser
Captures passing network traffic and can store it for later. Not only does it gather traffic, it presents the information contained within the packets in English, and not things like Hexadecimal, unless of course the content is encrypted.
Wherever we can sit and soak up data, wired or wireless , the analyser can do its job. Which is any of:
- Viewing traffic patterns and determine what ports/protocols are in use between the machines we’ve eavesdropped on.
- Identify unknown or unverified traffic. We can see fragmented packets that come into the network and whether or not it is an attacker trying to do something malicious or whether the content itself really needed to be split up.
- Verify that packets are being dropped by things like our packet filtering reverse proxy and security controls are being adhered to.
Establishing a protocol analyser can be done in a number of ways, first is the most devastating where a switch or rogue AP is used and this is the physical device which can soak on data on its own. Other ways of sniffing traffic would be to use a tool like Wireshark , but in tandem with the corporation’s own infrastructure - so assuming you have entered the network to a degree already.
Network scanners
A tool designed to probe a network or system for open ports. They can determine what services or operating systems are running on a remote device. With a network scanner, you can set a target IP address or even a range of IP addresses , and it will report back what it discovers. Network scanners can even be used to create a visual graph , or map , of all the different devices on a network and how they are connected. These can be regularly used to ensure that we’re not falling victim to a system sprawl. A network map is a nice visual representation of the topology admins have put in place, like all the subnetting, mesh networks etc.
We use this tool much like an attacker would. We want to understand what systems on the network have openings that could be exploited. After determining what services are in use, we can make an educated determination on which should be allowed to stay open, which are no longer needed, and those that can be disabled. Network scanners can also be used to determine whether there are any rogue systems on the network, by seeing SSIDs they don’t recognise, like the ones an attacker may use for their protocol analysers…
Wireless scanners are specialised devices that aim to crack open wireless networks and expose flaws in the communications, individual devices and encryption techniques. They can either be passive or active, the former being a simple listener which takes in all broadcasted traffic , whilst the latter is querying the AP for things like its SSID , or in the case of a WPS pin cracking attack, it will be constantly querying the router for the 8-Digit PIN (supplying brute-force guesses) until it gains access.
Banner grabbing
A type of scanning is called banner grabbing - a banner being a declaration of a particular system attribute - like an Apache web server version, what OS is running, banners that aren’t always present to end users but are nevertheless given to the wider world. We can make use of this public information and build up a profile on the target, so it is the role of the organisation to either obscure this data, replace it, delete it - this should mean the attacker needs more connection attempts to pull anything, hopefully getting them discovered by security personnel.
Password cracker
Password crackers are used to battle against the encryption scheme a corporation has employed. Security professionals often run crackers against their sensitive accounts to test their strength.
Vulnerability scanners
- A network vulnerability scanner probes a network for old router versions, outdated protocol standards, individual hosts and such.
- Host vulnerability scanners look more at the operating system, open ports , not so much its role on the network here.
- Application vulnerability scanners are utilised when we want to see application strength i.e are they the right version, are they configured properly etc.
Configuration Compliance Scanner (CCS)
CCS are used to inform admins when their configurations don’t meet standards, and the Security Content Automation Protocol (SCAP) automates these configuration checks. We can check for a variety of configurations:
- Operating systems and their version
- Installed programs or applications
- Settings of the network
- Presence and settings of antivirus
Compliance baselines should be establushed and examined over time. In most cases, these tools aim to create a baselines on their first operation so that we may measure deviations in future scans. Over time as our programs change , operating systems get patched this baseline so too changes and it follows along and advises our system along the way. Essentially a Configuration Compliance Scanner will be given a file by the admins which may represent something like the firewall rules for a Windows system and we check the file saved with the configuration we want to see. Obviously these scans are quite intrusive, and these are normally credentialed scans, so the scanner itself has access to all the files it wants to verify.
Exploitation Frameworks
These are tools that unskilled attackers will use to find vulnerabilities in a system. Metasploit is a great resource for finding vulnerabilities in the browser, OS , applications, device drivers etc. They have the vulnerabilities ready to be used, they just need to be targeted - with the victim IP and port - and then you run it, game over.
Data sanitisation tools
These are tools used to destroy , purge or otherwise identify for destruction specific types of data that are sensitive but no longer needed. There are a few methods we use today:
- Whole disk overwrite. In most cases one complete overwrite is sufficient, but it is important to understand that some industries or organisations require multiple overwrites to ensure that any data can even be interpreted.
- Using self-encrypting disks is super handy too, as we just need to destroy the key and it should take longer than the remaining time left in the universe to brute-force.
An identity finder is one tool that can look for individual files or folders that we want to either keep or destroy.
Steganography
Write a message , paint over it. People in transit seeing the image have no idea that it hides such data. Now this isn’t combining the data and the image or whatever and then encrypting it, it’s just mixing in the data wherever it can and will use simpler techniques like bit manipulation. This steganography technique involves tweaking the least significant bits of a sound or image file to form a string of bits, in between these other bits, that enshrine the message itself.
The other method is to use the excess space , or white space , of a file and using this slice as the place where the message shall be written. Moreover, you can input a message into a regular file without changing the file size, as that space had already been allocated - you’re just using that area now. Keep in mind though that the hash of the file obviously changes, and you may be able to use this to your advantage to see whether a regular image has been obfuscated.
Honeypot
Honeypot is a server designed to look vulnerable , but rather than having real data, the data within is fake.
Honeynet is a collection of honeypots to mimic an actual network.
The general idea is to have the same monitoring tools on the honeynet that we would have on a real network which would give us an idea of how the attack was carried out so that we can defend our real servers from a similar attack.
Only problem is though that we may make the honeypot too enticing and depending on the design, we may lure the attacker into doing things that they were forced into, sort of like pulling a trap door and blaming them for snooping over all this data. Such tactics would be called entrapment and it raises ambiguous legality.
2.3 Troubleshooting Common Security Issues
With this chapter we shall be covering pretty much every attack vector that could arise, and could hence become a common security issue for each department - starting from the easiest and the simplest to the most sophisticated attacks a corporation could be expected to be hit with given a certain scenario.
The simplest and most dangerous security issue are unencrypted credentials. These are incredibly easy to attain, as the barriers-to-acquisition is just a packet sniffer like WireShark. In today’s day and age most insecure protocols get wrapped with TLS certificates and such to encrypt the actual data, but there are still naked versions of FTP , Telnet and SMTP which all send credentials in plain text. Even wrapping them securely doesn’t mean that their poor underlying architecture won’t exposure weaknesses - to the actual server itself and not such much the data, the actual design of the server being another security issue.
This brings me onto my next issue, with servers possibly needing patches, or they frequently mess with sensitive data it is important to log events and their anomalies. Logs should be captured for every network device which communicates with the server(s), and their events. The goal is to understand when there are anomalies, which are abnormal events and or data that stick out from the standard flow, helping us identify things like the severity (was this an attacker trying to bypass a firewall or genuine anomaly?).
Sophisticated logging and auditing software for finding these sorts of distinctions are called Security Information and Event Management (SIEM) products. They aim to provide a suite of products that aim to help business keep control of their network and their corporate resources. An SIEM sits at the top and can aggregate data from any different sources.
A SIEM software suite can include any of the following products:
- Log management, which does what it says on the tin which is to collect and store messages and other audit trails (records of system admins denoting points in system behaviour - breaks, resets , patching).
- Security information management (SIM) , and this is to do with the actual analysing of log data , correlating patterns and producing reports and storing both the logs and the report data.
- Security event management (SEM) , this is the other half of the SIEM suite, which includes the monitoring of events (sessions) , notifications that arise from those sessions and console views , meaning you can see the real-time changes to your data and the current state of the server.
- The next one can be thought of as an added extra, but it is also its own standalone service, and that is Managed Security Service Provider (MSSP). As with other providers, this is synonymous with networking connections, provisions like bandwidth , the security of these channels and they also offer network monitoring services. There can also be a disaster recovery in place.
- Security as a Service (SECaaS) . This is more to do with the client side, but they can apply to other networking device as well - as the services typically include the installation of anti-virus, authentication mechanisms like Kerberos setup, anti-spyware and intrusion-detection software. Outside of that the SECaaS provider may include Penetration testing and scanning to see if the configurations and general architecture are robust enough to thwart off attackers.
Directory services like LDAP are one of the main concerns and one of the main things that an SIEM suite will hope to secure, as they are one of the most precious gems in corporate infrastructure.
The next big thing to watch out for are permission issues and access violations. Aside from logging it may be that our system becomes too secure to serve clients and employees, for example the permissions we give user accounts may be too strict so as to prevent them actually being able to conduct their day to day tasks. We need to start from the position of least privilege, but it should be enforced as sufficient privilege , to get the standard business functions out of the way, and ideally the admin being able to cover for more critical business functions. It could also be that the user permissions are too powerful, and employees have access to resources not needed for their job. Role-based access control should be used, so if an employee bounces around departments it should be perfectly fine seeing as our role-based AC differs per department and keeps them in check regardless of their travels.
Access violations are when a user tries to access a resource they shouldn’t have access to, which may be due to a genuine mistake and it was a flaw in the role-based AC that granted them access, not the fault of the employee for purposefully trying to gain sensitive data; On the flip side it may be a genuine take of being too restrictive, which happens in more sensitive industries, but this false positive can be easily corrected with one disgruntled phone call. Worse would be a false negative, where we let attackers in without us noticing, so it could be an insider, or an external attacker that was probing and trying to access a resource they shouldn’t be.
Again, this is why monitoring resources is so important and it would be things like LDAP which would be probed , so it is important to get a firm grasp of standard behaviour, based on IPs per department, common access times and such so that the stronger our idea, the greater the number of anomalies and (fingers crossed) the fewer the number of incidents.
Next up are Certificates. These are used to identify trusted users , devices or providers, and can also be used to provide encryption between two parties. Now, to get a real sense of what certificates actually are, please read Chapter 6 : Encryption and PKI , as you don’t need any other reference as it’s purely jargon and theory. Certificates are essentially declarations of personal information for a particular entity, alongside the signatures and keys that make us sure it is in fact that entity’s certificate, and it is that entity who sent it. Websites have to have a certificate if they want to setup an HTTPS connection, as within the cert is their public key for encrypting their messages. The browsers on our phones will warn us of a bad certificate, if the source can be trusted - maybe it says that the site is Google.com but upon further inspection the Certificate Authority who issued it was “GoDaddy”. Yeh I don’t think so… It is so important that all our devices do these sorts of checks so that we are always communicating with trusted sources online.
Companies can host a lot of internal resources, that they only ever want employees seeing. Moreover we don’t need a third party CA to issue certificates, but what we can do is give certificates to employees, as there is a limited number of them at any time, and we can see if they are who they say they are. The “chain of trust” so to speak, would be from the employee, maybe to the department, and then to the actual top, the most abstract, which is just the company name listed. What happens though when we see a certificate that doesn’t have this rigid chain of trust, do we still accept them or not? What sort of certificates can we give the guest accounts if any? A user can force this trust , but should we allow our servers to work with that? Because then we allow all sorts of bogus certificates.
Issues can also arise as certificates become old, and if we are the company that host a website, this will mean people will be dissuaded from going as we are now considered untrustworthy. We should keep on top of renewal dates.
Data Exfiltration is the most important aspect of any organisation: Algorithms that do stock trading for financial firms, unique recipes for bakeries, or more famously in today’s current climate of COVID, which was when the Russians hacked UK hospitals to get information on the right chemical combination for a working COVID vaccine - and not to my surprise they rolled out a vaccine, without the need to run clinical drug trials. This saves money and they beat the competition. We cannot allow attackers to steal data and export it from the system on which it resides, so we could implement things like encrypted drives, password protect files, restrict the access a particular account has to resources to mitigate damage etc.
Misconfigurations and Weak Security Configurations are, besides people, the only real reason a hacker can get in. Devices should be audited periodically to see if there are any updates we can make to the versions of the software that protect the device, like the OS , the firewall , the BASH shell…A simple example would be having a firewall installed on your laptop that didn’t follow the default-deny rule, which basically says for anything that isn’t within the rule-set of our firewall, just drop the packet. If this isn’t ticked, then anyone could send us a packet and we would consider it. Companies should check that the encryption algorithms used between employees and the wider world is of the latest version.
Personnel Issues. The weakest node to any network… As the days get longer and people feel overworked, it is only natural they make mistakes i.e leaving keys on their desk and forgetting about the clean desk policy, telling your friend across the room your password as you’ll be on holiday so you can’t login, violating the password policy - the list goes on. Even though we can put Acceptable Use Policies (AUPs) in place, and they can be clearly communicated we must have the worst-case scenario also in play. Policy training should be performed regularly so as to make it a habit, so for the aforementioned worker who feels tired whilst finishing, will simply clean his desk by habit and drive home (also by habit). Insider threats through are another reason why we should plan for the worst-case scenario as these agents don’t care about our policies and seek to abuse them!
Social engineering is another aspect of our personnel training, to help our staff sniff out people trying to scam them. Common formats of phishing emails, that sorta thing.
Social Media is a big one, as an employee could leak titbits of information over time that exposes quite a lot about operational processes. Organisations should have some sort of policy that outlines the procedures for their own social media, and the people’s own (in regards to the company).
Personal email if integrated with the company itself could become an attack vector and a possibility for data exfiltration. It also creates an entry point for malware, as the personal email could be used as a means of people to click on attachments. Personal emails should really be prohibited in the workplace.
Unauthorised Software, is software that may not have a licence ,many not be particularly rigorous i.e from a known source that does their own vulnerability testing. Many companies have procedures in place to make sure that this sort of code doesn’t make it anywhere:
- Run our own vulnerability scanners and compatibility testing systems to check if it would be safe, and if it would be compatible with our machine.
- Antivirus scans for checking known signatures of malformed code.
- Licensing checks.
- Ongoing support from the creator of this software.
A whitelist is super-powerful in this position, as we completely negate the possibility of having anything on machines that we don’t know about, and for something like this to pop up would be an IOC. It could even produce legal risks if we aren’t sure about the policy or if the company itself is under tough compliance to only keep certain kinds of software on their products. Good example might be if Instagram paired up with this Chinese Advertising company that ran adware, but turns out they were harvesting data… oopsie.
Baselining . This refers to the process of measuring a system’s current state to get some kind of reference point. Maybe this is for something like snapshots , where we need a clean, default configuration that acts as a base. Most organisations will have some kind of configuration base system for all machines, which aim to cover its current security posture, current bugs - with the resulting system configuration being the baseline. As we increase the size of our whitelist for new applications and things, then the new baseline must be reassessed and the creation of a new baseline is made. A baseline deviation is where the system changes from its original configuration, or the last frame - by removal , addition or both. Hopefully these deviations are only made by us, we don’t want to see some Windows Registry keys being tampered with , so what we could do is automate the scanning of machines, to check their baseline, so when deviations occur (such as own additions) now would be a good time to routinely update the baseline itself, and then the reports a clearer and we see if anything else has been done outside of our changes. Baseline deviations can be fixed automatically on some Windows environments as the Group policy will reconfigure the system to the baseline settings when they detect changes.
Licence Compliance Violation. Pretty much every piece of technology issued by a vendor has a licensing agreement, a document stating your terms of use, the agreement on behalf of the company and other legalities. If we were in a position where our licensing was invalidated , for whatever reason , maybe our license key was changed or lost , then we might find ourselves being unable to get updates or patches from the vendor :/ Depending on how sever the case, it may mean we can no longer supply our own products, if they happen to be reliant on these underlying products - and hence their licensing agreements.
Asset Management. Which is what it says on the tin, the management of computing assets: Hardware or software. Modifications to the system, baseline deviations are easier to determine and catalogue when we categorise our assets , as we begin to learn how often a year they typically get patched , compared to other assets. Patch management procedures can then be specialised for each system, to help ensure they stay up-to-date. It goes hand in hand with other processes that keep the business running smoothly. Valuable assets become easier to track, and what sits upon different assets (what programs are running on what hardware) becomes straightforward to discern. Licensing for each asset is tracked, and we can then trace the impact of an LCV.
2.4 Given a scenario, analyse and interpret output from security technologies.
Now this chapter will be focusing on establishing a degree of security onto a workstation computer or server. The different ways in which we can prevent network attacks, malware installation and general threat protection. This also involves being able to look at the logs so we can have our fingers on the pulse of all networked activity - just who is our computer talking to, where , when and what are they transmitting?
Installing a HIDS/HIPS
Now this meant to be installed employee computers or any of our corporate servers. It sits always monitoring network traffic, all traffic that flows through the NIC . You may have thought that it watches the processes of the actual host, but no it watches all the traffic that a specific computer is both sending and receiving. This way we don’t have to abbreviate or shorten any logs, the HIDS/HIPS can report everything - as we want to know everything - about the communications of this usually quite privileged computer. We could put a HIPS on a web server, that acts as the last line of defence for our corporate network, as an attacker may have managed to fragment packets and make it past the firewall on the router we can put this system on - assuming the traffic to this web server isn’t that high, so maybe sticking it on an employee portal. HIDS can also detect the communications of any software that makes outbound requests, which is what antivirus may miss , and attackers will often want to exfiltrate data over an encrypted channel - dodging antivirus , but if we configure the right rules on the HIDS then those funky ports can be flagged and admins alerted.
Host-based and web application firewall
Similar to the above, but with a greater focus on rules themselves (and not too much with things like signatures and heuristics , which are of themselves different ways of configuring “rules”) and the most common host-based firewall for Linux is iptables . This just defines the rules on the client for all inbound and outbound communications, with an example configuration looking like this.
A host-based firewall on every client, with a network-based firewall on the router is a good defence-in-depth strategy to have, but another option available to clients is the application-based firewall. Now, for the exam these things are defined as separate, because technically they can be done as such, but in most corporate environments a host-based firewall will also watch the activities of applications and hence become an application-based firewall. But it may be that we install an application-based firewall on employee computers so we can see what apps they use, and what traffic these send out. These are slightly different from a web-application firewall, which is a firewall that does extensive checking on the actual packets that go over the internet, and will inspect the packet for all sorts of oddities which may smell of malware, XSS etc. A WAF is typically hosted on a web server and adds in watching over the sessions with all its clients.
Antivirus and Patch Management tools
Now onto other , more internal measures. We will want to install antivirus as a means of watching over applications, key operating system files (which a HIDS can be pushed to do) and checking whether there is any odd behaviour that falls into one of the “malicious signatures”. Antivirus usually comes with the Operating System, but it can downloaded for OSs like Linux and it is mightily useful to have if you’re not particularly technologically adept or astute, and you may fall for smart Phishing emails - let’s hope AV can fight them off. Patch Management works hand in hand with a good antivirus, as it will be inevitable that the apps we have , and the OS itself will have some glaring faults which need patching quickly. Patching tools automate the deployment of these patches onto employee computers, so that companies can stay protected. Patch management also includes the company methodologies, which may be focused on testing and verifying patches , other companies may just throw them in as they become public. Admins may routinely runs checks against systems to see if their list of patches matches the ones they have and if there are any discrepancies then they may be pushed onto a quarantine network to update themselves. This same sort of checking is what NAC does.
Advanced Malware tools
This is very similar to antivirus, but on another scale. It is like antivirus for the network, and companies like Cisco have made their own Advanced Malware tools - called Advanced Malware Protection (AMP). They use analytics and continuous monitoring, which build up a good database for detecting anomalous behaviour. It goes way beyond standard file checking, and it can alert admins, prevent attacks from being executed inside the network and its logs are helpful in the state after an attack.
Insuring computer safety with application whitelisting and file integrity checks
These two are pretty simple things we can enforce on employee computers as most offices use Windows Domains , which means we just create the application whitelist and apply it to all Windows groups we see fit. This tutorial is a practical implementation of that.
File integrity checks involves checking the hash that comes with a file by hashing the contents yourself and seeing if any modifications were done to it over the wire. Now file integrity checking is great, if you know for sure what every letter of that file must be , or you trust the person who sent it to you. Otherwise it could just a hacker that is being ever so kind by providing a hash with his malware… Integrity must be coupled with authenticity.
Stopping the removal of data - Removable media control , DEP and DLP
Removable media is an absolute nightmare for security professionals , as employees may just pick up a planted USB in the car park and slot it into the USB drive… It is for this reason that DVDs, USBs and any other removable media are prohibited as the user can too easily just copy malware onto their computer…
On the flip side to reading things from the media, you can also use it to harvest data that is on the machine, and Data Loss Prevention is a set of policies and procedures that aim to negate this sort of data exfiltration as much as possible. DLP software tools may block the use of all flash drives, but they can also be more selective and allow some actions, by examining the data and seeing the labels associated with that data, so if it was rated “confidential”, then the action wouldn’t be authorised. Ideally we would want to see the file that was trying to be pulled, the time and from what folder. DLP solutions can be particularly nice against insiders, who want to print off confidential documents. A DLP tool can sit on the computer and see the data that is going to be sent to the printer, and if it is outside the whitelist then it can be blocked and logged for admins to see later. DLP tools can also see the contents of emails, as removable media isn’t the only way , nor are printers. A monster DLP solution would watch emails, FTP traffic, LDAP traffic, HTTP traffic, but then these are called network-based DLP systems. When outgoing encrypted data is going out of an organisation to a funny looking IP on a bogus port, now is the time to alert admins. Cloud-based DLP involves putting a system on the cloud that watches the data going out. Just because we can’t touch the server doesn’t mean we can’t secure it. The system can work both ways, for data going and if it sees someone trying to save confidential data to the cloud, like PII or PHI - of which it will alert security professionals as this may be outside of data confidentiality and privacy policies.
Data Execution Prevention is quite different to DLP , but the idea is the same : control and log nefarious activities outside the rules. Well, that’s the whole of Security+ I guess, but here DEP is a convention where an OS will set aside memory specifically for executables to run in, supposedly isolated from standard memory addresses. Moreover, when a virus tries to run outside of this scope it is blocked and detected. AMD calls this feature Advanced Virus Protection (AVP) and it is enabled automatically as a default for OSs like Windows to use and enable too - with their Windows Event Viewer.
Unified-Threat-Management (UTM)
This is the motherload of all security tools we could possible have at our disposal, aimed to sit on a server or admin computer and it can contain any number of the following:
- URL Filter and content inspection
- Malware inspection
- Spam filter
- CSU/DSU
- DDoS mitigator
- Firewall
- IDS/IPS
- VPN endpoint
It aims to simplify the workload of IT admins, as the Fat Hub is to the layperson. UTMs package all these tools together so an admin doesn’t have to configure them all and can start with a relatively high degree of security off the bat.
2.5 Securely deploying mobile devices
This chapter will be split up into sections, and when I mean mobile devices I mean laptops, IPads , phones - basically anyone which isn’t bound to a physical socket.
Connection methods for mobile devices
Cellular connections are those made utilising telephony circuits - such as 4G and LTE. Now the difference between these two , frankly , is ridiculous. Essentially, 4G is the fourth generation of wireless communications technology for mobile devices, with the telephony infrastructure being able to transmit audio and video, HTML pages and you can stream content too. LTE stands for Long Term Evolution and it is both an overarching standard for all “Generation” technologies, but if you see something like 4G LTE, this isn’t technically 4G. This is a bolstered 3G connection that just comes with greater speeds, though not the minimum that qualifies it as 4G. 4G LTE-A adds the “Advanced” on the end, basically saying you can do all the functions you would on a 4G network on a 3G one, its just not as fast. For a much clearer explanation than the one I have given you, please see here. Cellular signals are widely available across the worlds, and each cross section of land where there is a telephony connection is called a cell. The antenna in one’s mobile phone is strong enough to reach at least one cell. The reliability of this connection method means organisations can maintain constant communications with their employees, pretty much negating any geographical restrictions; although there will always be sections of land with very weak / no signal - in rural or remote locations - and depending on where an organisation is based may impact their ability to connect. But realistically such a dilemma would only exist for small, remote companies.
WiFi is a networking technology that uses radio waves , which is electromagnetic radiation - in this case the release of energy as waves - and these propagate through the air and are picked up by our mobile phones, laptops , the list goes on. We just need the proper antenna to pick up these signals, which can be done over various frequency spectrums - 2.4, 2.5 or even 5 GHz frequency spectrums are in use today. Getting WiFi setup in smartphones is a relatively simple task, it is cheap and the easiest to use solution. For spaces that can offer decent strengths and consistent signals, this is the go-to signal as it’s aligned with the mobile device philosophy of going wireless.
Satellite communications (SATCOM) rely on transmitters and receivers communicating with satellites in orbit. SATCOM relies on line-of-sight electromagnetic waves to act as our signals, which means a single powerful wave that hits the satellite in the right position. SATCOM is used in the military , for forces at sea or remote locations to provide communication, but we also have satellites on our roofs which communicate with other satellites. The only problem is the darn cost, making this a less desirable solution.
Bluetooth is a short range , low power wireless protocol that transmits in the 2.4 GHz band. Bluetooth can be used to transmit and receive data from a variety of devices, most commonly mobile phones. Bluetooth is easily configurable , with no need for network addresses or ports. Instead, Bluetooth relies on pairing to establish a trust between devices. We should always have discoverable mode turned off, unless of course we are attempting to pair. Being constantly available leads to Bluejacking or Bluesnarfing attacks - where the former is about sending packets , issuing commands, and hijacking the device to do our bidding and the latter is about leveraging the discoverable mode to communicate with the device, to have it disclose all the data that it has.
Near Field Communications (NFC) is a wireless technology that establishes a radio communication when they are within close proximity to each other, usually 10 cm or less. NFC is employed to move data between mobile devices and mobile payment systems. But obviously by being in line with a user’s financial institution , this becomes what miners call a gold-vein. An attacker may be able to play a special film over the card reader, which remembers the signatures of the waves that flow to the reader itself, but then there is the problem of getting the film back :/
ANT (Adaptive Network Topology) can be thought of as a competitor to Bluetooth made by Garmin as it is a wireless sensor networking technology that is primarily used in sports and fitness centres. Even though it was developed by a private company, the technology itself is an open protocol and standard so companies can implement the technology into their clothing or whatever. The protocol has the functionality for basic data representation, signalling , authentication and error detection within a PAN (Personal Area Network). It is designed for use with sensors , such as heart rate monitors , fitness devices and geo-location sensors to provide individual performance reports.
Infrared , which is basically just used in TV controls. Again, like SATCOM it needs a line of sight. It can be used in connecting wireless devices, such as mice, keyboards and other peripherals. It works by transmitting a band of electromagnetic radiation below the red end of the visible colour spectrum. Being so weak it cannot penetrate solid objects, so devices that emit such signals must have a clear line of sight when projecting - no devices should be in the path. Now the frequency is lower, the wavelength gets longer, and so people can eavesdrop from a greater distance.
Universal Serial Bus (USB) has become the de-facto standard of connecting storage devices to transfer data to. USB ports have expanded the ability to connect external devices to computers without cables. Most of our smartphones today have the ability to transfer data to and from computers as well as charge their batteries via USB. Due to their high storage capacities and instant read-write abilities, USB devices can be used for quick theft of data and to bring malicious files into an environment, be it a single computer or entire network. For this reason most organisations have some form of control over what devices are allowed to connect this way.
Mobile Device Management
Mobile device management is a bit trickier than it sounds, as how we manage the device depends on whether it is completely corporate owned, or if it is the employee’s personal phone - in that case we can only manage the ways in which they connect to corporate resources. If a company does have ownership of the device they can install a Mobile Device Manager (MDM) which is software that can tune and control each aspect of its functionality. The configuration of the MDM is centralised, so the technicians don’t have to tweak and work with each device at a time, this would be insane for a company with 1000+ employees, so this combined with RBAC (Role-Based-Access-Management) will imprint a good idea of what is allowed/prohibited on a device quickly and accurately.
Application Management. Mobile app stores generally provided by the phone’s vendor are a way to install software, and they will do a varying degree of testing and vetting to ensure the apps don’t become a security risk. The code itself isn’t usually the problem though, what causes issues is the fact that apps need to reference to databases , how they handle keys is important and who (outside of the app - so the creators and even stakeholders shouldn’t be able to see the data present). TikTok is a great example of this: the app itself is secure, though the databases can be freely accessed by the Chinese government. Application management is really what it says on the tin… Just how strict are we when it comes to banning and allowing applications - do we just allow business-relevant applications? Some companies, usually those of a military affiliation, will build their own app stores so they know exactly what sorts of resources a phone will have access to.
Content Management
Information that is available to the mobile devices should be regulated, as per their department , their network and even the websites they can or can’t visit. Most organisations have a data ownership or data use policy (DUP) that states what data can be accessed and from where. Content management is a set of policies and actions that control not only corporate resources, but the sections of public resources that corporate devices are allowed access to. It may be that authentication servers are set to recognise particular certificates , which only the mobile devices have, and to reject requests, as the information shouldn’t be accessible via this medium - probably due to the fact applications could peer into this information bank and glean sensitive data easily.
We could have functions that look and new data, and key markings on it to demarcate what sort of “sensitivity level” the corporate documents are, and moreover what specific devices (or device types) can access it. Then we need to update our authentication servers and other infrastructures accordingly.
Push notifications.
Remote Wipe
Once an attacker is able to acquire one or more corporate phones or laptops, the problem then is that they have all the time to world to break our encryption keys, and chuck all of their resources into cracking our phone(s). In the event of theft, we need to make sure that we can wipe the device clean of corporate data, and so our MDM can have remote wiping enabled , and all we need to do is go onto the MDM web user interface and click “wipe” etc. Although we don’t always have to do this, we could simply establish some kind of “wipe if password entered is wrong 3 tries in a row”, then we know someone is trying to break in.
Geolocation and Geofencing. Geolocation is what enables geofencing, which is the ability to create a virtual fence , or simply change configurations on the MDM based on a device’s Geolocation - this being the act of establishing the location of a device, oftentimes used for recovery purposes.
Geofencing is so unbelievably useful though, as it creates two worlds - the office and the outside world: So you cannot access corporate servers outside the office,
Authentication measures. Now onto the own user’s authentication side of things (but the company nevertheless has policies on) . It is important to have a screenlock on your PC, mobile , laptop as you don’t have to remember to lock or suspend your computer each time, it stops an attacker who walks by having full access to your system; likewise the unlocking should have something to do with a PIN or password (which adheres to password strength policy).
Biometrics is another method of unlocking our device, resting on our genetic uniqueness i.e fingerprints and facial recognition. For the exam it is important to know that biometrics aren’t classed as a proper security feature though, but a convenience feature. This is due to the ease at which current biometric sensors can be hacked or duped.
Jumping from user -> device authentication now to user -> resource authentication, where the context-aware scheme is employed: essentially asking the following questions:
- Which user is trying to access this resource (credentials)?
- Which resource are they trying to view (server-side data)?
- What is the current geolocation of the device (GPS)?
- Which device is making the request (device in use)?
- Which connection method is in use (wired or wireless)?
Containerisation and Storage segmentation. We’ve talked about containerisation briefly in a previous chapter, when we wanted to run standalone programs on a server, and we can employ the same sort of idea to mobile devices, where we containerise the personal data and corporate data into their own “containers”. This way the MDM only needs to secure corporate data, and can update the OS underneath that section , and leave the personal container up to the user’s discretion.
Storage segmentation is also about logically separate units, but this is more focused on storage, what drives will take up containers, as we could have logical volumes, which allocates space on both drives, but to two separate containers. Neat thing about logical volumes is you can encrypt the sections of the corporate container, which are in the personal drive and keep this standard of security.
This partial decryption isn’t a great idea though, as we know that users can take photos of themselves in the office, not knowing that the whiteboard behind them has their network IP address on it for example. This could mean attackers wouldn’t have to decrypt the corporate container, as the personal one is filled with gold. So , as a sort of insurance policy, it is better to have full device encryption. Most phones have a trusted platform module built in, so it isn’t a challenge to set this up to work for the entire storage medium. Only the user has the key (i.e password) which unlocks the device and can decrypt what is on there, otherwise it is just jumbled bits.
Monitoring and Enforcing Mobile Methodologies
Mobile device policies should be consistent with those existing computer security policies, they should be treated like any other device that sits within our corporate infrastructure, as it talks to servers, uses resources and executes business functions. If we don’t pull our weight and slack on the security measures here, this becomes a major attack vector for hackers; moreover training, disciplinaries and the ability to monitor should be implemented so as to reduce the possibility for exploitation.
App stores
- Apple store for IOS devices
- Google Play Store for Android Devices
These are third party repositories , which differ in their security requirements, as the Apple Store is quite stringent in what it allows, after all it is the aesthetic and “proper” way to use a phone, whereas the Google Play store is more laid back. This leads to a disparity in the trust we can give the average application from their stores. We also need to think about how much freedom we give employees to download applications that find their way into the App Store, as the code might be clean but what if the database is linked to the Chinese Government (TikTok) ? Managing the usage of these apps, through the right training or whatever, and the usage is critical. We can install on an employee’s business phone (if it is under COBO or COPE) certain Mobile Device Managers, and then create a whitelist of applications. We don’t mind if an employee installs Slack as this is good for business, but Candy Crush isn’t !
Rooting / Jailbreaking
These are two terms which refer to bypassing the inherent controls of the mobile device’s operating system , rooting is the common term for Android devices, as we are getting to the root of the system, and within touching distance of low-level OS controls, and bypassing any of the restrictive ones. Jailbreaking is the term for IOS devices, and usually refers to the sidestepping of built-in limitations, they are really the same but I would say Android routing has more potential to completely take over the phone - with Jailbreaking you can install another App Store called Cydia , which then allows you to download mods, blocked apps and all sorts, then the fun begins. The owner can now operate the phone at a privilege that was not intended, but really this isn’t too bad as the people that do this should be those with the know-how and awareness,there is also the chance of gaining some extra utility from the device (if you ignore the damage and voided warranty) and obviously given the prerequisite that the company has allowed that to do it (fat chance haha).
Continuing on this thread, sideloading is one of the superpowers we can get once we jailbreak or root our device - although if the security configurations on the phone are weak enough (if the “install software from remote sources” box is ticked) then we can sideload without rooting . Essentially it gives the user the ability to download applications without having to go through authorised channels (app stores). Sideloading is so much easier on Android as you can just tick the box to allow off-market applications, but with iOS, you must first jailbreak or get an Apple Enterprise Certificate and you have the privileges to download your own apps. It goes without saying that the probability for downloading malicious software goes up exponentially.
Custom Firmware
Now whilst this could go under the last section, custom firmware can go under its own for some of the unique functionalities it offers. See, when we root or jailbreak we have the ability to rewrite the firmware present on the chip (ROM chip specifically) , and this may mean we can add new functions which could be needed by the company to get the phone interacting with critical infrastructure better , or to have access to critical data though this is mightily rare. It should only really be used on low-ranking devices, not on Executive suite devices :sweat_smile:
Firmware OTA Updates
Firmware, as all software does, requires updating. As these devices are mobile, however, bringing the device to a central location or plugging them into a computer isn’t always an option, nor is it practical. Nowadays the device’s app store will receive an update packet, and this alerts the main settings. We then get prompted to click “Update” or something along those lines, and the updates will run over WiFi. Whilst vital updates and patches get included, for any company that has a hefty MDM configuration, these updates may influence the power of the MDM itself, and for this reason it may be that updates are stalled, checked and then granted.
Carrier Unlocking
This is where we can add another SIM , replace a SIM on a given phone for another carrier with no hassle . In the US though mobile devices are locked to particular phone carrier (Verizon being the equivalent of say Vodaphone). If you want to change the SIM on your device in the US, you must contact your carrier so that they can unlock your device. The process is completed by entering a key sequence that allows the device to sever itself from the carrier. Similar to how Microsoft texts you a verification code for outlook. Just like with jailbreaking / rooting , this severing can mean our MDM is effectively useless, but depending on whether the mobile device is a personal device or not will influence whether or not you can disallow one to go through with the carrier unlock.
Camera use and recording microphones. With the use of a camera or microphone on a device it may be that an employee at work takes pictures with friends, not realising the information on the whiteboard behind them is confidential data. The microphone or videos can discern secret conversations, take recordings of business meetings and such; also if an attacker were to break into the device this may be the first they do to perform next-stage reconnaissance. If the device is company-owned , and the device is used for illegal purposes , this could create liability issues for the company. For the user it may mean losing photos and videos during a device wipe initiated by the company (again, with the phone being owned by the business).
A good way for an MDM to limit camera and microphone use, but not to enforce a ban on them altogether would be to geo-fence this functionality to the office. So when the employee leaves, then they are all turned back on again.
Short Message Service (SMS) and Multimedia Message Service (MMS). This is the communication channel over cellular networks which mobile devices use to send 160 character messages (in the case of SMS) and multimedia content like photos, videos etc (in the case of MMS - like iMessage). And with everything else there is some sort of policy on what you can and can’t send…
People can message us with spear-phishing attacks, if another employee’s phone was compromised for example. Details can get leaked that can disclose financial accounts or worse. This functionality could also be geo-fenced , though I can only see this really being implemented in a military environment.
External Media. This refers to an item or device that can be connected or disconnected from a computer whilst it remains in use. Examples could be an external hard drive, flash drive, speaker and even smartphones - as we can connect them via USB. If it can store data, then it will be on the radar of an attacker. External media is such a powerful attack that hackers have in their arsenal, such things like a rubber ducky USB which is mistaken by the computer for a keyboard can execute malicious scripts at startup and really do some damage. Simple data theft can also occur, when an attacker brings their own flash drive, plugs it into the laptop and hoovers up personal and corporate documents, and then goes home , reinserts the drive and downloads the data. How we use our external media, how we store them and when we use such storage devices should all be included in the policies…
GPS Tagging or geo-tagging . This is where photos, videos, documents and messages could have location information embedded in the data - most often times in pictorial formats. Obviously we wouldn’t want to have photos of where our data centres are, a photo of when our security guards swap shifts with the clock in the corner showing the time…
USB OTG and WiFi Direct/WiFi Ad-Hoc.
As we know USB devices are those that make use of the USB port in laptops, PCs etc and can then transmit data between the two. USB On The Go (OTG) is where we have a USB cable with two ends attached for devices to plug in either end, and then we can get the same kind of data flow. The mobile device can be both a host and a receiver, there is no need for a third party storage device , as the phones do this functionality themselves. But obviously such convenience has consequences , as an attacker could just plug their USB cable in, with their device and the mayhem starts.
WiFi Direct allows two devices that are WiFi enabled to connect directly without the use of a wireless access point - which is different to a WiFi hotspot which is an access point, creating a personal hotspot is called tethering (relying on the mobile data power of your carrier). WiFi direct uses the same WiFi technology, just without the other network components, a connection isn’t really established, it just becomes the very rudimentary bouncing of radio waves between two close mobile devices. The two devices can share services across a single-hop connection. Because Wi-Fi direct uses the same wireless technology for the internet, now reserved just for these two devices, it means neither device can access the internet. Though it can be useful, and this drawback may not be noticed. For instance, you may use the printing services on one device from the other device. WiFi Ad-Hoc performs the same functionality but with multiple devices, and due to the extension of the wireless technology to use multihop wireless communications, each device can use the broader internet. We shall cover ad-hoc in general in the next chapter (3.2) but in principle it is just the means of establishing a connection without the need for an intermediate - an AP.
Tethering is essentially turning your phone into a WiFi router, just one with absolutely no defence. So it basically just becomes a WAP for malicious attackers, though the timing would have to be incredibly unfortunate, it’s not like a Starbucks hotspot (a WAP for public use) which is on all the time.
Payment methods. With the advent of the smartphone and the applications that sit above which link to our financial institution, we can pay with our phone or with contactless payment - which both use NFC (near field communication) . This form of payment utilises the built-in security features of the device, like PIN , biometrics. The device itself is kind of like a hardware token for the transaction.
Deployment of Mobile devices
The deployment of mobile devices also depends on the type of corporate infrastructure available, because we need to make sure that we have the appropriate security procedures in place, and the right kind of staff, where if we were to do something like BYOD (Bring Your Own Device) this wouldn’t cause massive security issues. Maybe we just allow them to enter a secure channel into our employee portal, and the firewalls, certificates etc are enough to push hackers away. Maybe we just offshore the resources on the device itself to servers, and we setup their device to act as a kiosk, an access point to the server which has virtual machines for each employee. BYOD is also called BYOT - The T stands for Technology - as it may be more than just devices it could be Personal Computers, Monitors, Printers etc. It should go without saying that these devices which are brought in need to be vetted to some degree, what are the OS versions, are there any malicious applications on it, does it combat WiFi attacks etc. But here in lies the truest problem: That this device is also for home use, so some technician can’t come in and know everything about it, make tweaks all the time, make the drives encrypted etc. What happens when the device is sold or traded in?
Choose Your Own Device is a bit better, as the employee gets to pick something that they would feel comfortable working with, but without it being able to be taken home (or maybe it is, depending on policy). But the plan is to isolate one’s office and home work, without compromising on productivity. Also, company now has control over the device, they can make changes without being too intrusive, as the employee knows the score here. Another very similar option is COPE (Corporate Owned , Personally Enabled) and this is where a company will just choose the device that the employee will use, but with the same office and home use included. CYOD is also good because it should limit the total number of different technologies that technicians may have to grapple with.
With these last two, information can be deleted at any time which may be unnerving to an employee who sits waiting for the inevitable and constant checks and tweaks, but you would have to be silly to throw all your personal photos, documents etc onto this device, this was only meant to mimic your ideal home environment.
Corporate Owned Business Only (COBO) devices are taking out all limbo of home and office and it were a device is bought simply for work , and this is usually because it has more sensitive data on it, and it shouldn’t be mixing with personal information. Things can be expected to be updated, mended and secured on an as-needed basis.
As I was nattering on about slightly earlier , many companies are now using a Virtual Desktop Infrastructure (for corporate owned devices) or Virtual Mobile Infrastructure , for any device that may be anywhere in the world. The applications and data are both centralised, and decoupled from the mobile device itself - making it much more secure , and we can put most of our efforts in securing the connection , than having to meddle with the actual user. Once someone is in, we know exactly what kind of functions we can give them and we can log communications , whereas we wouldn’t have been able to do that (as we cross over too much into one’s personal privacy) - but seeing as its our virtual machine its fair game. I’ll assume all VMs have the same OS, and in this case it would be a lot easier to develop applications for this platform, then for one where everyone had their own infrastructure; moreover these apps would only needed to be updated on the VMs, which we have control over, so another win for VDI/VMI.
2.6 Implementing Secure Protocols
This chapter is going to focus on taking our standard protocols , which were invented back in the day when communication was of much greater value than encryption. We can still take the packets that these protocols generate, but what we need to do is make the tunnel with which they are sent through tremendously harder to sniff, to crack and therefore to prise open. Tunnelling can be done with certificates which encrypt the HTTP packet or what have you with the public key, and then they are decrypting on the client end with the private key. The establishment of this secure session can be done with RSA, then the communication begins. This is what HTTPS, FTPS , SMTPS are all doing.
DNSSEC
We can also make the Domain Name System (DNS) much more secure, by employing this same PKI (Public Key Infrastructure. This chapter is going to make so much more sense if you go through chapter 6 first). We don’t want to do what the secure protocols above do - which is encrypting the entire communication stream, we just need to prevent forgeries so that the client is always sure of the direction they take when surfing the web. When you think about it , it’s just like solving the problem for forged road signs by sticking a government QR code that your car reads as it goes along the motorway, always validating that the government made them and nobody else. Now the same questions arise: But how do we know these signatures cannot be faked? Well, this is where the asymmetric key infrastructure comes in.
The first step is to group all DNS records of the same type into a Resource Record Set (RRset). So if our little DNS server had only three AAAA records (for IPv6 addresses remember) then they would all be bundled into one AAAA RRset.

Now this RRset is what gets signed, not the individual records, those are hashed alongside the certificate of the DNS zone server. All these new keys and signatures are given their own DNS record type:
- RRSIG : This is the signature for each RRset.
- DNSKEY : This is the public key which will be used for signing records
- DS : Contains the hash for a DNSKEY record.
There are other records, but for the principle of building a secure infrastructure this is enough.
For each DNS server zone, there is a Zone-signing key pair (ZSK) , the private key and public key of any asymmetric architecture. The private key is for signing the entire RRset, so each record type is supposed to be paired with a signature that says - “These records are all from a particular DNS zone server”. The public key, the ZSK available to anyone can then verify the signature.
I don’t want to confuse you with the ZSK and the DNSKEY . The private key of the ZSK pair is what signs entire resource sets, the DNSKEY signs records, and the DS will hash this signed record for the client to compare whence the record is received.
RRSIG is what keeps all of these signed RRsets.

So , just to recap. The private key of the ZSK key pair will sign each RRset. This creates the RRSIG you see above. When a requester asks for a particular record type, we give them the corresponding signature of the record type they requested, but then we also need to provide them with our public ZSK , otherwise they can’t verify the signature. We take the RRSIG and the public ZSK, use that to decrypt their signature, and we should get back the RRset, the entire collection of records for that type. We then need the original RRset that the server gave to us and we can check these two pair up, because if so much as a single record changes, then we know to drop this and run away.

Now this only checks that for a ZSK key pair , the data they encrypted went unspoiled. But what if the ZSK key had been compromised and a man in the middle was able to then give us all the pieces we needed? For any DNS resolver, how do they trust this key pair to begin with? In truth, we need a key , from a higher authority , that signs these ZSK keys… Say hello to the Key Signing Key (KSK).
We can see from the image above that the Public ZSK is stored within one of the DNSKEY records, amongst the keys which work on the record level, the ZSK works on the RRset level. Now, we can do the same process we did for verifying the RRset for verifying the key itself: We take the DNSKEY RRset , which has an RRSIG generated by this Key Signing Key , and lastly we use the public KSK to decrypt the signature and see if the DNSKEY for signing RRsets is the same one we see in the RRset we got given raw. This sort of checking at the atomic level is supposed to build up a brick, and when combined with all the other DNS zone servers doing it is supposed to build up this wall of security.

So the RRSIG here was signed by the private KSK , and we then try to decrypt it with the public KSK given to us in the RRSET. This should allow us to check the hash, and voila we can confirm if the public KSK has been altered.
DNSSEC Protocol details
Moving away from the intricacies of the protocol, let’s discuss the ports and protocols. Old DNS had smaller packets, as there was simply less stuff that the client needed so packets didn’t need to be broken up and given over a session, hence UDP got by. Obviously the case isn’t the same here, with DNSSEC needing to use TCP (same port 53 though) as the packets can be much larger.
For more on DNSSEC , view here:
Secure Shell (SSH)
Secure Shell aims to make it easy and secure to log remotely into another person’s computer. This TCP protocol is another big proponent of asymmetric cryptography, and the two computers that wish to communicate must have their respective RSA keys ready. The transaction is done typically over Diffie-Hellman and from there we can begin our asymmetric conversation.
One user will issue an SSL packet, which could also be a tunnel for other protocols as we will see with SFTP, to access other services present on the computer but it can just be a remote admin tool.
SSH typically uses port 22.
FTPS , SFTP , TFTP and SCP
So FTP is secured within a TLS tunnel, I don’t say the SSL/TLS as SSL is deprecated, much too weak. Transferring files this way though is pretty secure, and this service runs over TCP ports 989 and 990. 990 is the FTPS control port, and is where the connections are established and it is separate from port 21, so older devices can just connect there , and then be rerouted. 989 is the data flow channel. Keep in mind this implicit use of FTPS has been deprecated, and clients will need to make a specific request to use FTPS services if they want to.
SFTP is the use of FTP over an SSH channel. The file rides an SSH backbone , so you need to sign into that computer via SSH first i.e some-user@192.168.170.188 and then the SFTP shell opens up for you on their machine and you can manage the files and directories on that machine, transfer data to and fro and this is pretty convenient.
Trivial FTP is a protocol that was designed to do small packets of data - hence trivial to transfer - and this is through UDP port 69. The only problem is that this protocol has not fought hard enough against some of the inherent security issues with UDP , and makes no effort to authenticate who is sending data or where it came from - never mind checking these credentials for authenticity.
SCP , or Secure Copy Protocol is designed really just for quick transfers, not really for the degree of remote management you can do with FTP, but it’s quick to just send a file to a remote server or something. It also makes use of an SSH backbone, and hence it uses port 22 also, but the Secure Copy Protocol itself is much weaker, outdated and hasn’t been maintained - so for this reason stick to SFTP , or FTPS…
SNMPv3
Simple Network Management Protocol (SNMPv3) is a management protocol (Woah really?!) that both device and manager (router, server) need to understand; moreover devices on the network that provide crucial services need to communicate their status to the central network node, most often a router - though it could be a separate server that manages these signals. We specify version three specifically because there was a significant change to the protocol to reflect the necessary changes, as many vulnerabilities existed in prior versions.
Any device on our IP network can be managed, and the manager itself issues packets from UDP port 161, while alerts (the lingo for this is traps) are issued by clients to UDP port 162. Alerts can be anything from overheating, crashing etc.
Simple Mail Transfer Protocol (SMTP), Post Office Protocol (POP3) and Internet Message Access Protocol (IMAP)
These three are all in the business of helping you send, retrieve and manage emails as easily as possible - but they all have slightly different functions. The one that isn’t much related to the other two is SMTP and this is for sending out mail, using port 25 normally but in the case of a TLS tunnel then port 465 is used. Ports are kept separate for backwards compatibility and the extra processes that occur when things flow into that port (decryption or encryption).
Servers will also use the protocol to send (relay) from mail server to another. This relaying is important as people may use different email providers.
The relationship between POP and IMAP , in principle , can be thought of as the same dynamic that SCP and FTP have. The former is for simple jobs, a single message , but the latter when you need to take a peek into the server itself, send more than one messages and have more functionality at your disposal. POP3 is the latest version and it is used to retrieve email messages.

Authentication features are necessary to prevent malicious individuals from gaining unauthorised access to users' messages.
Generally speaking, a POP3 client retrieves email in the following manner:
- Connects to the mail server on port 110 (or 995 for SSL/TLS connections).
- Retrieves email messages.
- Deletes copies of the messages stored on the server.
- Disconnects from the server
Although POP clients may be configured to allow the server to continue storing copies of the downloaded messages, the steps outlined above is the usual practice. Leaving them on the server is a practice that’s usually done via IMAP. Let’s talk about it now.
IMAP (the current version being v4) communicates on TCP Port 143, and secure IMAP uses TCP port 993. It allows users to group related messages and place them in folders, which can in turn be arranged hierarchically. It’s also equipped with message flags that indicate whether a message has been read, deleted, or replied to. It even allows users to carry out searches against the server mailboxes.
Here’s how IMAP works in a nutshell:
- Connects to the mail server on port 143 (or 993 for SSL/TLS connections);
- Retrieves email messages;
- Stays connected until the mail client app is closed and downloads messages on demand.
Notice that messages aren’t deleted on the server. This has major implications, because if you are keeping the mail server yourself then space will be used much faster, than the simpler POP3 methodology; although there’s one good reason to use IMAP which is the fact that it stores messages on the server, meaning you can retrieve messages from multiple devices; sometimes, even simultaneously. So if you have an iPhone, an Android tablet, a laptop, and a desktop, and you want to read email from any or all of these devices, IMAP would be the better choice.
If you end up caring more about privacy though, POP3 doesn’t leave messages by default, meaning the server is cleaner.
Secure Multipurpose Internet Mail Extension (S/MIME)
MIME is a standard, that was actually drafted for SMTP , and it was designed to help that protocol work with data - like photos, videos etc in formats that were not ASCII, hence the name multipurpose extensions for email. Clients can use this content type when sending emails, and the following headers will be added into the packet for you by the email client application:
- MIME version.
- MIME Content type , so is it just plaintext, or are there any attachments too?
- Content Disposition. Based on the above it will either be inline, where it is just a message , or Attachment Content Disposition, meaning there is additional data the user will need to click on to be displayed.
- The actual encoding that the email should use.
The encoding itself isn’t encrypted, so if you have something like Wireshark, you can parse MIME encodings and have at their data :) This is where S/MIME comes in, and adds to the standard with an additional set of security headers, which now allow the inclusion of digital signatures, an encrypted payload and so opens the doors to public key encryption. Now senders can sign their emails with their private key (to give an aspect of authenticity and non-repudiation), and most email clients will have this functionality by default - which is pretty sweet.
S/MIME has changed the game for email, as now we include certificates - most commonly a type of certificate with a .p7b file extension. This certificate holds the certificate chain - so the user’s certificate and all the people who issued the certificate , and then the people who issued the cert in the layer above etc. This chain of trust can be put in every email automatically, and someone can check the signature and know it was us.
Secure Real-Time Transfer Protocol
RTP is a protocol used to provide audio and video data , and the interconnection and improvement of RTP gave birth to VoIP. This protocol is used mostly within applications, as it is not a standalone service in itself, but applications predominantly use it - and so the application port will change frequently. The Session Initiation Protocol (SIP) helps to determine the connection between two computers (unicast session) , or between a group (multicast). This last method , of signals going to many computers at a time , is what discourages these protocols from using TCP - which prioritises reliability over timeliness. It would be lagging and jarring to have to speak to a group of friends, employees etc with this sort of connection. Whilst RTP does use UDP it’s aware of things like out-of-order delivery and coordinates things as quickly as possible. SIP creates the session, and the payload is the RTP packet with the audio/video data.
Network Time Protocol
NTP is the standard for time synchronisation across servers and clients, using UDP port 123. If a company is for whatever reason paranoid, then they can use SSL/TLS tunnels to hide this information and this wold be NTPsec. The reason for this is that each server in the overall group which need to be synchronised with each other typically have some sort of certificate to say - “It’s really me” and hence we have the terminology NTPsec , but another thing to note is that SNTP is reserved for Simple Network Time Protocol , which is an algorithm that does simpler calculations to find a time for servers to synchronise to, but it won’t be as accurate.
LDAPS
LDAP Secure is the implementation of LDAP which makes use of SSL/TLS. This tunnel is on port 636. This method was actually retired though and is replaced with the Simple Authentication and Security Layer (SASL) as LDAP is flexible in how it authenticates clients, as we have seen with Kerberos, practitioners of LDAP wanted more flexibility in their architecture which SASL gives them, but overall there are many security improvements that come with LDAP version 3.
Read about the differences here :