CompTIA Security+ Chapter 3: Architecture and Design
Table of contents
| Sections |
|---|
| 3.1 Frameworks, Best Practices, and Secure Configuration Guides |
| 3.2 Secure Network Architecture Concepts |
| 3.3 Secure System Design |
| 3.4 Secure Staging Deployment Concepts |
| 3.5 Embedded Systems |
| 3.6. Secure Application Development |
| 3.7 Cloud and Virtualisation Concepts |
| 3.8 Reducing risks through resiliency and automation |
| 3.9 Physical Controls |
3.1 Frameworks, Best Practices, and Secure Configuration Guides
Frameworks are conceptual blueprints that should be used to define our network topologies, department subnets, access control lists, Standard Operating Procedures (SOPs). The list goes on, as frameworks are just overlying theories. Reference architectures go with frameworks, and are specifications of the current shape of our system(s).
Frameworks should define the security controls we should put into place as we architect our networks and systems. The puppeteers of power.
Reference architectures should be able to take a framework, with whatever plans it has specified and give us examples and pointers on how these controls are actually implemented to maintain compliance.
Here is an example reference architecture that Microsoft gives some of its clients:
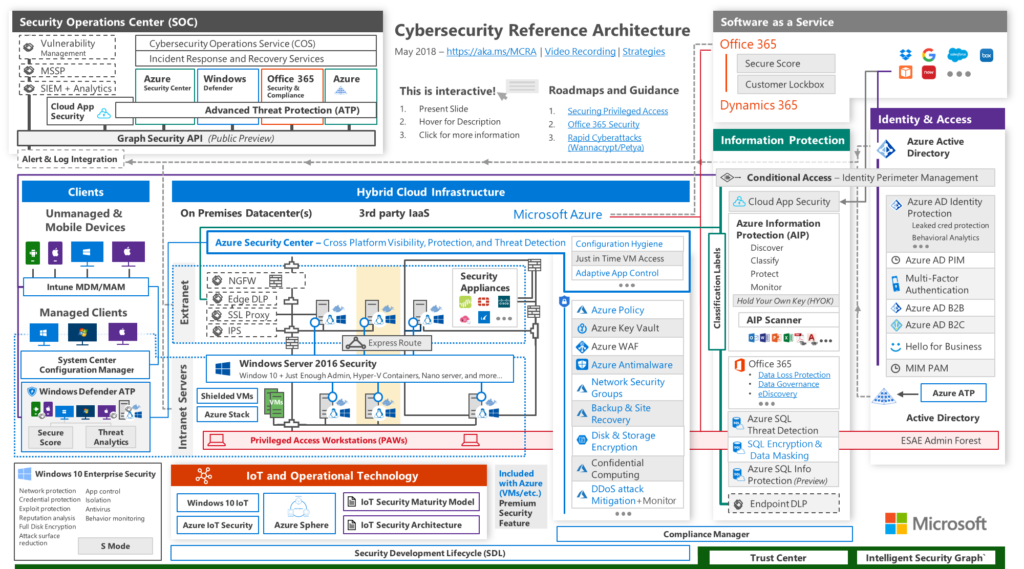
Regulatory and Non-regulatory frameworks
One of them is mandatory compliance with a standard , the other one isn’t … Healthcare, financial institutions , government organisations and electric companies due to the sensitive nature of the services they provide, extra precautions must be taken. For healthcare companies , hospitals and the like it is likely they will have to adhere to the Health Insurance Portability and Accountability Act (HIPAA) as it mandates the protection of PHI.
Non-regulatory frameworks are schemas (security control specifications) that are only mandatory for governments, as they take it upon themselves to be extremely , well , tedious with every single service, device you name it; whereas for the private sector, a lot of standards like the National Institute of Standards and Technology (NIST) are only optional. Companies can incorporate such standards if and when they please, though being able to show cooperation with tougher measures shows a degree of rigour and organisation. An example being that companies can choose to integrate the Control Objectives for Information and Related Technologies (COBIT) which is a brief that many organisation could use to ensure that business goals and IT security goals are linked , and included within each other.
Standards also span geographies (National versus International), as GDPR famously did, and from the EU it forced its presence onto America, which had to create the EU-US Privacy Shield Framework that was developed as a framework to facilitate those companies that do business in both locations. There are also industry-specific frameworks that provide guidance on how systems should be architected. For example, there is the Unified Extensible Firmware Interface (UEFI) that was the latest standard to govern the implementation of firmware for new hardware, and to establish a compliance, an agreed upon “style” that all users of said firmware can then understand and apply to any machine that has UEFI on it; as a business, it would be a bloody nightmare if you had to try and troubleshoot more than one computer that has absolutely no software that pertains to a standard… that’s many long nights pulling your hair out.
Besides industry-specific guides, there are also vendor-specific guides, so Windows guides on their Operating System usage, which shouldn’t vary depending on the manufacturer of your computer. Likewise, if you use Linux use a Linux guide, although there are nuances to that, but the rule still applies.
Security configuration guides
Guides for how to properly configure a given system’s configuration, to enforce a degree of robustness. SCG’s are often called benchmarks. These benchmarks are designed to help industries , or specific organisations, find a set of security controls they can rely on, and possibly tune to their needs.
These guides come from three major sources:
- The vendor or manufacturer of a given service or system
- The government
- Center for Internet Security (CIS)
Security Controls
A security control is designed to make a particular asset or information secure, by doing something to the system itself (improving its own configurations, removing unnecessary apps and ports) , or to add something to the asset or system , maybe adding biometric sensors to our locks, or adding encryption to all our files.
- Administrative controls, those that carry out the management functions of the company, such as policies , planning risk assessments etc
- Technical controls are those that operate on a technical level on the systems. This includes authentication mechanisms , software firewalls, IDS/IPS.
- Physical controls are those that operate on the “tangible level”, something that we touch and see. So things like locks, security guards, bollards etc.
Regardless of the class of security controls, these will aim to perform a particular type of function. So this might be to prevent someone from accessing the building, as is the purpose of a fence , or it may be to detect someone - like CCTV . All this and more is covered in section 5.7.
The need for User Training
User training , getting the most vulnerable part of the organisation properly educated, and adherent to security policies and procedures , and having them report suspicious activity (and knowing what suspicious activity looks like) will be paramount to a good stronghold. Regardless of the control class
Defence In-depth
DID refers to a security principle in which multiple security elements are employed to increase the level of security, a composition of controls if you will . These should ideally layer in such a way that they fill the potholes left by the other layer below.
The basic idea is that if one layer is being explored by a hacker and penetrated, the other layers above should provide adequate defence to exhaust the resources of the attacker. Remember , if they had all the time in the world, then it wouldn’t matter how many layers we make, we aim to deter and to challenge these attacks, always shrinking that window of compromise. In networking for instance, this could be the use of a hardware firewall, coupled with an Access Control List and IDS/IPS present on routers, and additional network segmentation to reduce visibility of all connected computers. Computers themselves could tune network settings , to drop ICMP echo packets for example, as these are commonly used by nmap to get information on a victim.
Vendor diversity is a good way to improve defensive sophistication. E.g using both Linux and Windows.
Control diversity is where we have many different classes of security controls , with each of them using different security types.
3.2 Secure Network Architecture Concepts
I’m afraid it’s time to understand how we can best secure our network, but don’t fret ! It’s quite simple. A network is simply a linking of different devices, through an agreed means of communication. We have a standard of communication in our local network, and we have to adhere to the standards outside of our network (unless we want it to be purely local).
Typically we have an intermediary server, that sits in between the outer world, and our internal corporate network. This buffer zone is called a Demilitarised Zone (DMZ), and it should have a firewall screening potential inputs, and we should also have a firewall setup on our internal network.
The idea is to have an additional funnel, that does a “general rejection” of candidates, much like an interview process first rejects by CV , and then comes the next round of closer inspection. Demilitarised zones should contain things which we would want the wider world supplying information to: web servers and FTP servers are good examples. Where it gets trickier is that the DMZ can also house Remote Access Terminal (RAT) servers, which are things like employee portals, which ideally should sit on the internal network (so requests can be twice screened) , but we want contractors , freelancers etc the chance to login. Obviously this is the one that should be watched over the most.
Network segregation
The word greg in ancient Greek meant “flock”, and what we aim to do with our network devices is put them in the right flock , as they typically speak a certain sub-dialect of the overall network and perform more specialist tasks. The typical department is subnetting by departments, and sticking a switch on every department floor that PCs connect to. This would the physical segregation, which requires separate hardware and cabling.
Now if you think about it, even though we have segregated the hardware, puts switches in and such, they are still all part of the same network. There is no air gap. What we need to solidify this idea is an ideology, a logical manifestation of separation that leverages our topological designs. Logical segregation is basically instilling some logic into things like routers, which can check incoming IPs, and if that requester has permission, via some associated token or whatever, then the packet may be forwarded.
Now then, aside from computer to computer communications, a local desktop can spin up virtual machines, and enough of them can serve as “imaginary friends”. These VMs can communicate just as well as their hardware counterparts, that is if you give them networking permissions etc. The management of all these VMs is delegated typically to something called a hypervisor , which (for the average client) sits above the OS and manages computer resources for these images.
So just to recap, we need to understand the means of securing a packet between two nodes, and also the nodes that sit above other nodes (VM to PC).

Intranet and Extranet
An intranet (inside-network) is just like having your own internet, with servers holding resources on corporate data, websites hosted by web servers etc, but they are all controlled by and within the scope of the organisation.
Extranet (extra-network) is the extension of our intranet via the connection which other organisations, possibly being in the same industry or in connection with external agencies (Microsoft and the NSA cough cough). Extranets are semi-private networks, as an attacker now has a “spoofable” opportunity to act as an employee of this outside company and doesn’t need to work as hard to push through the DMZ and such.
Wireless Topologies
The hub and spoke topology , or more commonly known as the star topology, is a type of network layout that has a hub at the centre, through which all devices will send and receive data through:

The mesh network is the last one, and it involves the use of multiple , overlapping access points to provide stronger wireless coverage, and the bonus is not only is there no single point of failure, but a user can walk through these network ranges and their devices should automatically reconnect to the closest one.

Guest networks
A guest network is a network that is supposed to be isolated from systems that customers, visitors or guests shouldn’t have access to, without authorisation. A guest network is setup by making another access point on one’s router, and we give the credentials of this AP to guests, and leave the credentials of our actual, home AP to the devices we own. Guest networks are good for corporations to have, even on the internal network as this handles BYOD (Bring Your Own Device) quite nicely, as we allow them internet access, but not the ability to modify any internal resources.
The main differentiator of these networks is just credentials, though it will make that little bit harder for an attacker to break in, as the guest network is the only one open to new connections. An attacker could communicate with another device on the guest network, but ultimately we leave them only one option which is to break into the router itself.
Air gaps
No data path exists between two networks, moreover the network is immune to any wireless attacks coming from outside of the external network.
Tunnelling and VPNs
Now in this little subsection there is quite a bit of meat to it, but I’ll take it one step at a time.
Tunnelling is a general idea, and it involves embedding one packet inside another essentially - it is what we do with secure TLS connections, we take the encrypt TLS packet which has the encryption keys for the other end to read it, and the payload would be our HTTP packet - in the case of an HTTPS network. VPNs take this idea of tunnelling to make it possible for us to link a remote client into a secure private network, and/or to connect two distant networks as well. It may be we have a contractor in another country who needs access to the private network, so what we would do is give him/her a file which contains the IP of the remote network, a certificate from us and for them , and a private and public key for setting up the secure connection. If you ever want to see the file itself - just make one with the openvpn tool, yielding a file like this one.
So the VPN client will attempt to initiate a connection to the VPN server. Our request will start and go through to the ISP first, but they can’t do much packet inspection as we have encrypted our payload and all other contents (apart from the source and destination IPs) towards the VPN server. We This tunnel can be done using all sorts of encryption methods , but EAP-TLS seems to be one of the best ways to implement it as we have certificates to authenticate a person and trust that it is truly them. One the tunnelled connection gets the thumbs-up from the firewall - which sits at the border of the DMZ - it will be routed through to the VPN server. Now for the actual authentication process it may pass on the credentials to a RADIUS server, which could have a database of credentials , or it passes it on again to the LDAP server. But in reality, it is most common to see an LDAPS server be the one that verifies credentials. This is due to the fact that we may have many remote employees, all within different groups and having different permissions, and LDAP is built to handle this sort of group hierarchy model and can articulate the user better than a simple RADIUS DB.
Besides EAP-TLS , other companies may decide to go for SSTP (Secure Socket Tunnelling Protocol) which uses TLS over port 443. It is useful for when the VPN tunnel we have must go through a device using NAT, and other solutions like IPsec - which we will discuss in a moment - isn’t feasible.
When we get a lot of employees , as is the case for larger organisations , we might need a VPN Concentrator which , much like an SSL Accelerator , is designed to optimise a particular type of connection and offer significantly more bandwidth to handle these new encrypted streams. It sits inside the DMZ, and will be handed VPN traffic by the firewall.
This is how remote access VPNs can be optimised, and by remote access I just someone who has multiple devices but has the right certificates on them that allows them to connect from anywhere. We will have our VPN client which connects to broadband, then to the ISP , and then along the internet to establish a connection with the concentrator. A site-to-site VPN is one which aims to establish a tunnel between two networks instead of a client server model. Moreover, there is a VPN concentrator at each end to facilitate these connections. They are typically used between companies that have their offices separated by vast distances , but want to keep transmission secure. It extends their intranet out, and negates the inherent insecurity of public lines.
Another method of encrypting data-in-transit is to use IPsec , which is a suite of protocols to encrypt IP traffic , and we can make VPN clients use this infrastructure - for things like remote access VPNs or site to site connections.
IPsec can work in two modes. Tunnelling or transport. Tunnelling, as the name suggests, is better suited for the VPN mindset as it encrypts the entire packet, so good for going over the internet; whereas Transport mode only encrypts the payload , whereas the only things visible in Tunnel mode is the source IP of the VPN client and the destination - to the VPN server.
When a client wishes to connect to a distant VPN server, and they’re using IPsec , this will be done over port 500 and this is where things like key sharing , using the Internet Key Exchange Protocol (IKE) . As for the packet itself, IPsec adds a few fields : The Authentication Header field (AH), and the Encapsulating Security Payload (ESP). This is why tunnel mode is important , as IPsec adds some many of these little headers that it is important we encrypt those if they need to go over the internet - if you use Transport mode you will not receive the option to integrate these wrapper protocols onto your payload.
The Authentication header will make use of the key we shared use IKE , and it will run a users details through HMAC (hashing the credentials and then encrypting with the key). This way someone on the receiving end can know that the contents haven’t changed, and that only a trusted person could have sent this AH. Using ESP will encrypt the data and hence provide the confidentiality part.
Split-tunnel vs Full Tunnel
A split tunnel is where the VPN client will recognise what traffic is meant to be routed to the private network, and the browsing that you do outside of that IP shouldn’t be rerouted; whereas with a full tunnel all browsing and internet traffic must be rerouted through to the private network, now you can imagine this may create a few issues where one now has geofencing issues , and a slower bandwidth unnecessarily.
Always-on VPNs
This is where the VPN provider and the client try to sustain their connection as long as possible, and this applies to both site-to-site and remote access VPNs. With site-to-site , in the corporate environment we may leave these two gateways running , so that all employee computers never have to worry about sending plaintext traffic across the network. We can also use an on-demand system to give the illusion of perpetuity and start up the client sends a request to the VPN server.
It can also be configured on wireless devices, so the VPN client always starts up as and when the client makes a request.
Network Architecture Zones
Aside from the standard wireless and wired connections which have both become ubiquitous , there is also the ad hoc mode of connection, which requires no Access Point (AP) - as two devices can send signals to each other in a P2P fashion. You would usually use an ad hoc connection method if you wanted a brief communication with someone , like exchanging files over or connecting a blue tooth device to a phone.
Aggregation switches
Now I understand this topic is a bit out of place, though it is in the objectives so I will mention it. An aggregation switch is simply one which connects other switches together from other subnets. You would do this when you want to reduce the number of ports that you’re switches are using. With an aggregate switch we can get this down to one.
Taps and port mirrors
Another separate topic , and this one is about capturing and monitoring traffic that would otherwise be going through encrypted channels. A physical tap is one that redirects the cabling of computers, like so:
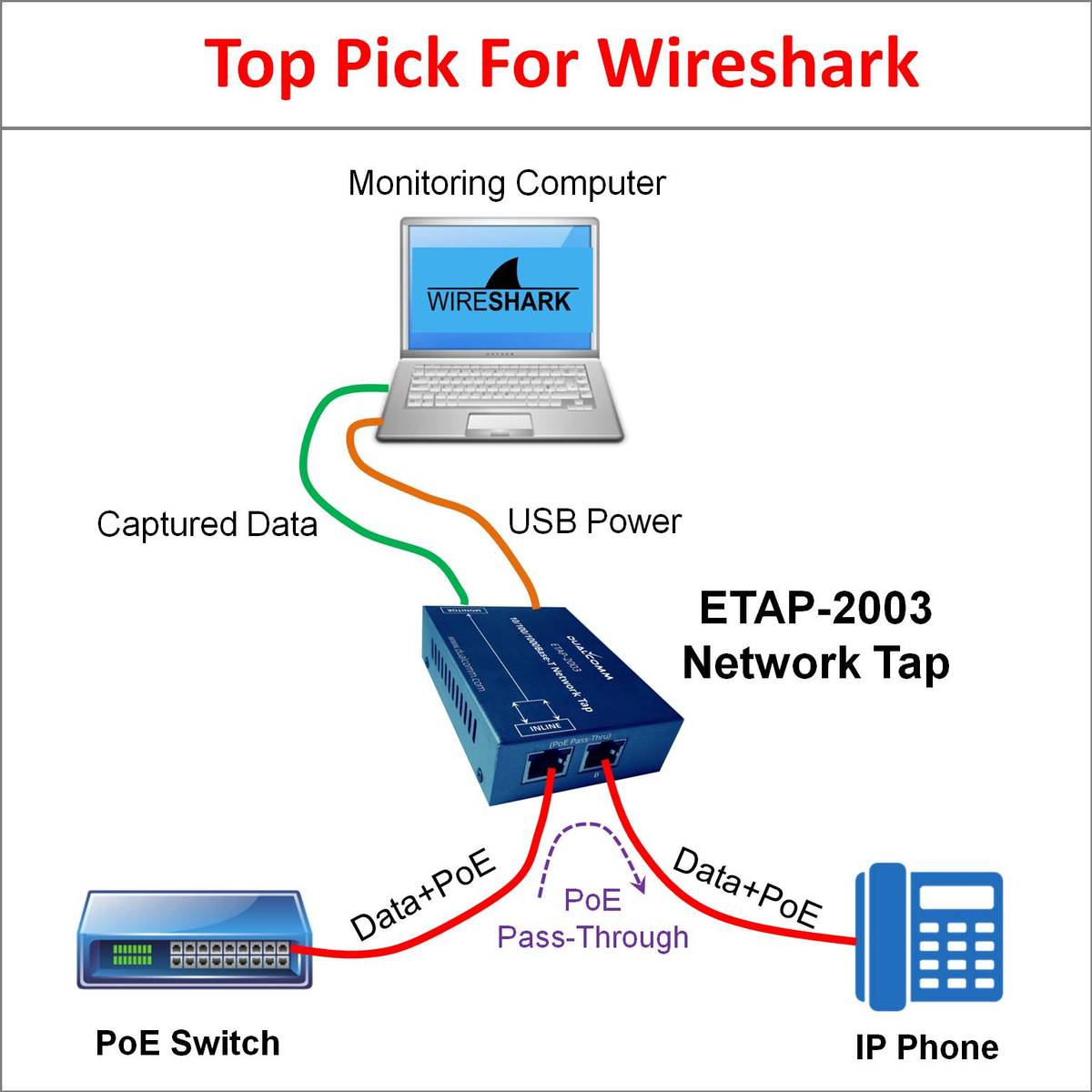
A port mirror is the software version of this technology , embedded into the logic of a switch, so that one port is both the port for a legitimate , normal client computer and the same port is then mirroring the traffic to a monitoring computer. Being that we are snooping at such a low level, you would hope that only the technicians and security personnel could implant this… Clients may be trying to setup a secure connection between sites the company has banned, and with taps we can see if they are trying to break the rules.
3.3 Secure System Design
System design , at least in the grounds of the CompTIA Security+ exam splits it into two sections: Hardware, and software, though are many complications that arise above, below and in-between these two fields I will only mention those that are immediate, and relevant.
Hardware and Firmware security
Physical security should be in place to prevent the theft or damage to hardware. Preventing theft can be as simple as erecting electric fences, putting servers in monitored server rooms. Mitigating damage can be done through strong cases, proper cooling, distributed workloads (so the CPU’s don’t burn onto the motherboard). In the exam itself, it is likely you will get a performance-based question , asking you to match the right protective equipment to the right device, so cable locks for laptops , door locks and surveillance for server rooms etc.
Firmware is what resides on a little separate flash memory chip that sits on the motherboard, and this is the first program that gets loaded when the PC turns on, anything before that is calibration. Due to the job that firmware has, we need to make sure that we are using the latest version, carrying patches against current threat vectors. Things we can do to improve firmware security would be to disable the debug interfaces and put passwords on terminals, as attackers (if they steal the device) will use these portals as a means of compromising our system. Aside from firmware updates, secure boot is something which deters threat actors like script kiddies, as what this does is allow our firmware to monitor key Operating System files, registries and such , only allowing the changes we sign off to be made. Of course if an attacker has our admin password that’s a different story… but blunt blades shall no longer hurt us.
Firmware on devices like Android tablets don’t really have a solid system for authentication and a chain of trust for who is actually issuing these firmware upgrades, and it is relatively easy to spoof the manufacturer in this case. The display of the device needs firmware upgrades, and I could just pretend to issue one out, but really I’m logging all information on the screen and at any moment I could take over the display with a pseudo-ransomware.
Full-Disk Encryption and Self-encrypting Disks
Due to the frequency with which laptops, phones etc were stolen, FDE and SED’s came onto the market, which makes sure that every bit stored on our hard-disk is completely scrambled, and only when we log in would be able to work with what’s on disk. Some cryptographic solutions go a step further, and have a physical key which you put into your hard drive, turn and then you have it unlocked.
Trusted Platform Modules, Trusted Boot and Secure Boot
TPM is another chip on the motherboard which is used to store and generate keys used to authenticate to its system. TPM much like secure boot protects against unauthorised hardware, firmware and software modifications by hashing sections of their respective code bases, like registries , executables etc (these encrypted sections are what are called modules) and seeing if the before and after hashes are the same (checking whether the blocks changed). Without admin authorisation , these updates will be denied. What’s great about TPM is that it exists separate to all other software components, the keys are not accessible via normal buses, not your PCI but instead your LPC (Low Pin Count) Bus, used for legacy devices or the TPM chip. SPI (Serial Peripheral Interface) is also a possibility which is a bus used for embedded systems in a very short range.
TPMs can do what is called a trusted boot. This is where each part of the boot process, from the UEFI/BIOS to the bootloader and then to the kernel can all have their critical infrastructure hashed, and these hashes are checked along the way. It prevents malware from being included in the malware as it would have to change the OS code that boots at startup (to be included in the startup list).
Secure boot is only possible with UEFI and some sort of TPM chip, or equivalent TPM technology present (a substitute is Intel’s Platform Trust Technology - PTT). It works with the keys and capabilities that TPM provides to then work to secure this boot chain. TPM stores and loads the hashes into registers called the Platform Configuration Registers (PCRs), which secure boot references along startup like so:

Moreover, drivers within the kernel are signed and the system vouches for us that they are still absolutely fine
Hardware Root of trust
A Trusted Platform Module is an example of the hardware root of trust, it is an isolated, simple system that our computer has assigned the most trust towards, and we let it dictate when our system is safe, and when it is in jeopardy. The root of trust is accomplished by isolating the hardware from the OS and the rest of the system so that malicious software cannot tamper with it.
The TPM designers realised that the simplest idea for a pure system is just data, and a few wrapper instructions around that data. It may be tempting to build a whole host of security measures , but if it is “air gapped” so to speak, if it just acts as a repository, which can generate, encrypt and decrypt items.
Hardware Security Module
Hardware security modules are proper blocks of cryptographic functionality, and will harbour keys as well, but to unlock the computer it is connected to, a physical key must be inserted (like opening a door) . These hardware security modules are capable of generating keys, decrypting keys and all these jobs are not having to do be done by the host CPU , which is a huge performance advantage.
They typically connect via USB and can be used to sign certificates, decrypt certificates from the corporations own CA, sign emails etc.
Electromagnetic Interference and Electromagnetic Pulse
EMI is an electrical signal , which disturbs the flow of other electrical circuits. These signals can be emitted via electromagnetic induction which is electrical action produced by a non-electrical source by converting energy into electrical energy - this energy thus disturbs our circuit. Examples would be washing machines, electric hobs etc.
An EMP is an electromagnetic burst of current in an electronic device as a result of a current pulse from electromagnetic radiation.
These signals can thus tamper with the electromagnetic signals we have on our system, and to mitigate this we have shielding wires, conductive metals that steer the electric signals to this overarching layer of cabling, and grounding is the connection of wire to the ground, so as to disperse this electrical signal into the Earth, and out of our rather poofy hair.
EM Radiation can actually be captured, and the pattern and intensity of the radiation can give experts a degree of accuracy on what the released radiation represents. For example, this happens when servers get hot as they overwrite large parts of their drive. Anyone with an EMR sensor can capture this energy and work out have a go and cracking the original signal.
Types of Operating Systems
Network Operating system - provides the actual configurations and computation portion of networking.
Server OSs - are used to bridge the gap between server hardware and the applications running on that server, usually optimised (not coming with the Microsoft suite for example… and they are tuned for concurrent processing).
Workstation OS - exists to provide a fully functioning working graphical interface for an end-user to interact with the system and its applications.
Appliances are standalone devices which have their own OS , but these are embedded systems design to perform and operate over a single function.
Kiosks are also stand-alone machines, usually setup for interactive customer applications. The customer is usually operating a browser instance of Windows OS , that is locked into the specific website.
Mobile Operating systems are optimised for device capability , with drivers switched out, and functionality tuned to fit a mobile rather than PC. Main mobile OS’s include Apple iOS (a derivation of Mac OS X) and Android , a derivation of Linux.
Patch Management
New vulnerabilities are constantly found and exploited. Patches are released by the software vendors as a way to combat these vulnerabilities , whether it be in the form of removing specific functionality or changes made to the logic itself, should help the software walk down the avenue they intended without going down the alleyways of compromise.
There’s no point vendors releasing patches if you’re not going to update your device! Keep the system updated so you can receive this patches.
Vendors typically follow a hierarchy for how they release software updates:
- Hotfixes , are small software updates designed to address a specific problem with an application. These are generally focused on a subset of logic within a library, or particular action and can therefore be released very quickly in reaction to a discovered problem or vulnerability.
- Patches are generally more formal and are larger software updates that address several problems with an application or OS. They often contain enhancements or additional capabilities as well as fixes for bugs.
- Service packs refer to a large collections of patches and hotfixes rolled into a single package. These are designed to bring a system up to a known “good level” all at once, rather than installing several updates individually. This can happen with newly release products, new Operating Systems for example.
Least Functionality
Least functionality refers to a process where a system does what it’s supposed to do, and only what it is supposed to do, without room for much enhancement, as the hardware itself is quite simplistic. Any unneeded functionality present serves as another attack vector.
Disabling unneeded ports and services is a simple way to improve system security and follows this least functionality principle.
Secure Configurations
Vendors have no way of knowing all the needs of every organisation that buys their product, so they ship OS’s with a default configuration based on the inputs from their user community.
The process we employ to prepare a system to go into production in our organisation is called hardening. Sort of like applying battle armour before war. Hardening includes:
- Removing all unnecessary applications and utilities
- Disabling unneeded services
- Setting appropriate file system permissions
- Updating the OS and applications to the latest versions
We should also disable accounts, if there are any, and change the default password to one that has a high degree of complexity.
Trusted Operating System
A trusted operating system is one that is designed to allow multilevel security in its operation. This is further defined by its ability to meet a series of criteria , usually defined by governments.
Trusted Operating Systems are expensive to create and maintain as each charge much undergo a recertification process (as do updates that have Secure Boot installed, TPM hashes are updated). These systems are certified through the use of the Common Criteria for Information Technology Security Evaluation process, commonly referred to as CC or Common Criteria.
A trusted OS is meant to have the configurations, settings necessary to block viruses , and it is supposed to ensure us that only authorised personnel have the ability to view data on this device. The configurations of such OSs can serve as the Master Images for employee computers, though we may dial it down or up depending on their group.
Application Whitelisting / blacklisting
These two refer to the ways in which an Operating System may deem applications acceptable , or unacceptable for use.
- Whitelisting is stronger, as any application outside of the list cannot run. Moreover it is timeless, and if these applications do not update, and are not connected to the internet, they are impenetrable. The blacklist is the rest of the world in this case. We just need to update as we go along, when we are sure we want an application to run.
- Blacklisting just refers to what we know as bad. This is more reactive, as only after the attack has hit us do we know which applications should not be running on it. The whitelist is the rest of the world.
Peripherals
With some peripherals , and the way they communicate between the computer it can leave quite a few holes for an attacker to get in. Standard wired keyboards never have to transmit data through the air, the signal is encapsulated which is good but if we have a wireless keyboard someone can sniff for these signals, which are normally passed in the clear and hence the attacker basically has the same benefit as if they installed a keylogger on the PC. Nowadays proper wireless keyboards will encrypt the data using AES, but you wouldn’t have to look far to find a keyboard that didn’t. Another facet of keyboards which is important to consider is the Rubber Ducky USB - which is where a USB shows the MAC and signature of a keyboard, so it gets to be loaded very early on in the computer boot process, and hence any scripts that are on the USB get ran.
Wi-Fi enabled microSD cards are storage devices which can communicate with your phone over Wi-Fi and that allows you to take a photo, save it to the card, and then save it onto your computer without having to take it out. Now whatever the card hasn’t secure for network communications , that a router and other networked devices work hard to secure, then it’s obviously going to have some fundamental weaknesses. Without strong security someone could just snoop and pick up these signals, and this may be just one stream that an attacker picks up with their Rogue AP. The same can be said actually with the cameras themselves , as their firmware can be messed with and an attacker can spoof updates to them, send instructions to the firmware etc. CCTV cameras need to be weary of this too, as it could mean an attacker can log in and view what the camera sees, and so build a picture of where the “safe spots” of a building are prior to intrusion.
External storage devices are portable , albeit structurally inept at securing the data itself and can allow pretty much anyone to slot the drive into their PC and read the contents. At least password protect the drive , otherwise it’s the easiest data exfiltration ever.
3.4 Secure Staging Deployment Concepts
Sandboxing
Sandboxing is a type of staging environment that essentially quarantines or isolates a system from other hardware , software or networks, to probe specific functionality and to test the reactions of modifications to this system. This is common practice among security researchers who want to test the venom of viruses, and allocate them a section of the machine , typically done by executing them on a virtual machine. Interestingly , this technique is now so common that viruses are trying to see if they may be trapped in the simulation by looking at the resolution sizes of the computer that they’re running in, if they are the default viewport for VirtualBox, then it stops executing and deletes itself. Other viruses employ the use of virtual machines so that they can evade detection.
Sandboxing can also refer to segregating a system from the rest of the network, this may be temporary whilst technicians try to find the problem with the system (and if it contains malware that may spread to other networked computers). Once our sandbox is setup safe and secure, we can test software (hopefully) without causing damage or disruptions to the rest of the system (or network).
Most organisations will have some resources allocated specifically for sandboxing, development , general practice and experimentation. These environments are crucial for learning, and provide a level of isolation and and buffer, so as to mitigate any possible security incidents. For web developers, code is regularly tested on localhost servers, and code is ironed out and once the desired functionality is achieved, the changes get pushed out towards the GitHub repository, where it is reviewed once more, before being included in production. Code that is getting reviewed can only be approved to the next production environment by a special account that gatekeeps the production environment i.e a lead developer. Some development environments are controlled by the same account that controls production, but this is going out of fashion as developers craft a development environment that works best for them, and then the submitted code can be reviewed with them. Control over both development and production environment by a lead is usually done with things like chip design, which is a lot more complicated, and the development environment itself has the complexity of an actual production environment.
We don’t always have to use virtual machines though to create a sandboxing environment. If the company runs linux machines, and the virus hit their employee computers - then we shouldn’t have to use the bulk of things like VirtualBox , we just need the isolation power. This is where a tool called chroot comes in, which means “change root”, as in the root directory for a given user. The root directory, which is theoretically the top level directory where their access begins (assuming no user can escape that is). Admins have their root access at the root directory , whereas users would have access from within /home/alex for example. We could run chroot to designate a folder that the virus would be ran in, and we would throw in all the applications , scripts and things the virus needs to run.
More info on sandboxing and VMs:
- Does a VM protect you from harm really ?
- Protect yourself whilst virus testing with a VM
- Running a virtual machine that can only connect through Tor
Environments
- Development. This environment is configured for developers to develop applications and systems.
- Test. Is still in the land of development, in the sense that we are preparing for production, but testing is where we assume we have a snapshot of our project ready, and the actual architecture we will be working with is used here to see if the two play nice.
- Staging. If you think of the production environment as the live-action theatre performance, then staging is the dress rehearsal and it is meant to be an exact replica with which the entire team, stakeholders, and QA can assess and make changes to without worrying about breaking anything. After all is good to go, things get moved to the production environment.
- Production. This is where systems work with real data, interact with real users and perform business functions. Hot changes to this environment have the risk of breaking sessions with users, creating bugs in the product etc so we hope that we have enough time to test and vet those changes before pushing.
Secure Baselines and Integrity Measurement
A baseline is a known starting point and organisations make secure baselines, made with all the security configurations, patches and adjustments that would provide a strong resistance to attack. Secure baselines can then be used as starting points for other systems, and if we have control over all employee computers we can automate and release secure baselines to these computers - getting rid of things like default configurations on PCs.
After we have deployed our secure baselines, we want to monitor how they do - and if they change it may be because of the specific needs of that particular group or department , or if it may be because of compromise. Automated tools can watch over employee computers , and relay the current state of the baseline , matching it up with the one we deployed onto it. If there are baseline changes, much like the way a hash will change given the alteration of a single letter, we can see whether or not there is a breach or problem.
We can use vulnerability scanners to do integrity measurement, and they can report things like SSL versions, OS versions, are the right patches installed etc.
For remote computers where they become harder to monitor - we may use things like a NAC which sits in front of the private network and runs these scans to determine whether the client would be bringing any malware into the system.
3.5 Embedded Systems
Right, so embedded systems are quite interesting as there is a single function, and so a single point of failure you might think - but due to their closed off nature from the world they often perform their function without being particularly “active”, they don’t talk to other computers and mostly humans. This aspect makes them very secure, but let’s see what aspects of embedded systems could lead to compromise.
Embedded systems are components that have a chip, allowing them to do some basic function and in league with other smart devices combine to form a whole device. Each embedded subsection is given a task, which when combined perform specific functions. Examples include : Washing machines, phones , fridges …
Printers and devices that share the ability to perform multiple functions are called Multi-Function Devices (MFDs). This is so because printers can scan documents, copy documents, some of them can fax and you can send documents to them via email.
Each of these devices though make use of one or more CPUs, GPUs and need memory, an Operating System and power. Embedded systems don’t always have to use little things like microcontrollers, which are circuits that perform standard input and output functions, but they can be programmable and have an entire system present on the chip. This circuitry is called a System-on-a-Chip (SoC) and it works well with more complex IoT and embedded devices like cars.
Industrial Control System (ICS)
An industrial control system is where we have a lot of embedded devices all coming together and forming a network, as there are many different and complex procedures that need to be executed within the production of things like cars, rockets or even nuclear power. An ICS is the overarching coordination of these pieces into a network, which should be separated from the internet and have its own private VLAN that doesn’t talk to the router.
Supervisory Control and Data Acquisition (SCADA)
SCADA systems are essentially smart devices (composed of embedded systems) designed to watch over and control other embedded systems. SCADA is meant to automate the human aspect, and allow these simple systems to function without our watch, where SCADA is probably used most often is in traffic lights. See, the closed off nature of traffic lights, they don’t need to open themselves up to humans and the wider world, they just need configuration to be sent to them, and some overarching monitoring functionality, hence we use SCADA. They are a great monitoring tool in factories and power plants, and hence why pretty much all ICSs will have SCADA watching them and reporting their condition.
Traditionally, SCADA systems were air-gapped from corporate networks, meaning there was no data path between the two, and external media was the only way of traversing data. However, modern systems have removed this constraint, as they too became more extensible and interacted with humans more. Due to this evolution, they automate a greater number of tasks and now we have SCADA links to the corporate network (uh oh…). Remember your NIPS.
Microcontrollers
Now then this is here where I shall talk about the difference between a chip, a microcontroller, and a System on Chip (I’ve listed the uses and such of SoC down below). Let’s think about what a computer needs to operate : a processor with at least one core and instruction set, memory - in the form or RAM, ROM and/or flash. Microcontrollers will operate with peripherals and perform a single function, the device will send signals which land in the data register, and the instructions for this controller to use (for computing said signals) is kept in non-volatile memory and loaded as well. The resultant operation should then spit something back and the process repeats. Microcontrollers have seen widespread adoption due to their simplicity , and for complicated technologies like wearable clothing and smartphones they are the integral unit of a System on a Chip. SoC devices are those which include microcontrollers (MCUs) as their central idea and include things like secondary storage, I/O ports etc. See this stack exchange for the difference
Internet of Things (IoT)
This leads us on nicely to the Internet of Things, which are interactive embedded systems, that can be used to a certain extent like personal computers, mobiles and tablets as come with applications and mutable configuration. By reinventing the household , and what I mean is sticking chips everywhere we have gained complete control of our house, only downside is that if there’s a power outage we’re screwed. The Internet of Things comprises all of these controllable, embedded devices, allowing us to do things like start the washing machine from work, turning on the lights and heating as we finish shopping, installing a surveillance system . The list grows whenever you reinvent a device and stick some circuitry in there.
Wearable technology is another thing that’s gaining popularity. Biometric sensors, that measure heart rates or step counters to measure how far you walk.
Home automation is what drives the adoption of IoT, and as we can see functionality is king, meaning security is put in the passenger seat.
System on a Chip
This is what I was chattering on about earlier, but this is the formal term that technologies like wearable devices and smartphones rely on. It sounds silly to say smartphone now, as pretty much all phones nowadays come with a chip that allows them to do calculations. These chips have the end device in mind, and come with more programmable, system-level logic that can be configured, including the hardware and software needed to operate that device, built into a single chip rather than the multi-chip system we see in computers.
We can get away with this single grouping, because the tasks, graphical interfaces and ability is drastically smaller.
Real-Time Operating Systems
This now leads us quite nicely into what sits on top of this revolutionised hardware, usually an RTOS. These systems are meant to be working in real-time, meaning data cannot be queued for any amount of time. The input must be processed within a specific timeline, usually as it comes . Imagine someone having to sift through an assembly line for rotten apples amongst the bunch, their input has to be grabbed immediately, there is no queuing and putting to the side as another load is quickly on its way! We expect RTOSs to be pretty busy…
These go the other way of IoT in terms of ideology, as they don’t want to open themselves up and become configurable, like an Amazon Echo, they do one function and will not alter to do any other. Obviously updating an RTOS whilst it’s running is insane, as any event that interferes with their timing will cause the system to fail. We would have to wait and take all machines offline, stop production and then allow these devices to be updated. What I have seen some factories do is redirect the flow of production around this device , and to another that does the same function, whilst it updates. Though it depends on the design of the factory, what the function is (how critical, and how many machines do we have?), and how busy the company is. The ideology of an RTOS is very much the same to a microcontroller, just process the signal don’t queue or do anything complicated just match the stimulus to the table of instructions we have and spit it out and do the next job.
These systems tend to operate quite old versions of their vendor software, and they don’t have time to include the manufacturer’s latest patches. The patches themselves must undergo brutal testing to make sure that the timing of the device will not be disrupted, as this can mean production comes to a swift halt.
To have RTOSs be a viable option in your factory, your processes have to be smooth. If an input takes long than a few milliseconds to process, and another job comes along , the system will stop and report an error - so it is paramount that you have planned out your assembly line and taken the appropriate measures to limit risks as much as possible. For example, let’s say that the factory is reliant on being cool, in the case that we’re mass producing desserts for example. If the temperature is perfect then the process can be done quickly and we have few errors. But if hackers were able to break into the HVAC (Heating, Ventilation and Air Conditioning) system then they could crank the temperature up and the food spoils , machines start being unable to process this gloopy mush and the entire process breaks down. Moreover make sure that you can secure each item pertinent to production as best you can.
Printers / Multifunction Devices (MFDs)
Printers are a form of multi function devices, as they can scan documents , queue jobs , communicate with other computers on the network (which means adhering to a protocol and allowing network connectivity).
MFDs were designed to be as helpful as possible , at least within their scope and maximise their utility, moreover this is the antithesis almost to good security - keep a single function, solid and well tested to be included with other solid and well tested units. Moreover we have seen how many printers have buckled to hackers over the years.
Special Purpose Devices
Many industries use SPDs as they are essentially a collection of embedded devices, SCADA automations, coupled with an RTOS to boot. The ones noted in the Security+ exam include:
- Medical equipment. This is probable the most pertinent in regards to keeping someone alive, as they monitor heart rate, release blood and/or nutrients from reserves into the patient etc. This sort of task must be coupled with some sort of insurance, and there are standards which they must adhere to - The International Electrotechnical Commission (IEC) 60601 governs the standard for electronic medical equipment. The only problems with these standards is due to their strictness they don’t allow the patching of many vulnerabilities, and instead must be some other form of compensating controls.
- Newer vehicles rely on multiple computer systems all operating semi-autonomously to function properly. Like with medical equipment, standards have been imposed and in 2008 it became law that all cars must use a Controller Area Network , with buses to each microcontroller (circuitry that contains a CPU, RAM, and programmable I/O peripherals) to make sure they could communicate with each other, and if one doesn’t perform right, then the other can take over whilst debugging begins on that other chip. All this is done without a central host computer, just one checking on the other. The US Department of Transportation as well as other governments around the world are demanding stronger security measures, as hackers have shown (at conferences like DefCon) that these cars can be disabled mid-motion, they can be unlocked and make changes to the entertainment centre system.
- Aircrafts. A lot of the knobs, switches and buttons you would see on traditional aircraft have been removed, and have been designated to embedded systems to monitor. A lot of old gauges have been replaced with a nice touchscreen computer display that gives a lot more functionality. These new systems also come with the functionality to connect to the airport’s internal network, to receive instructions etc. Though due to the very fact that planes now are networked entities, opens them up to wireless attacks. With this obviously comes the slew of testing and overarching standards, and one of the key requirements is that recertification at the time of any updates, and due to the lack of time a lot of aircrafts (I’m talking commercial here) have, as I remember I think a normal day at Heathrow was seeing planes take off every 15 minutes or so. Although, with the current Covid crisis, this has probably given airlines more than enough time…
- Unmanned aerial vehicles (UAVs). These are gaining popularity within the military as it saves the use of manpower. These devices are remotely controlled and give the operator the ability to interact with the device’s cameras, sensors and processors. This control happens via a networked connection, most household drones use something like Bluetooth, but the military would probably encrypt the communication channel. Harder, but not impossible.
Some resources:
3.6 Secure Application Development
Before we sit down at the desk and start writing code , there will almost certainly be a process with which the company will choose to develop in - and if not , run ! Companies either opt for the Waterfall method which is where each stage of application development is done sequentially , or the agile methodology where we can go back to each part of the process and redo parts of it if we like. Now what are the different stages of software development you ask? Well,
- The first stage , for either method, would be to gather requirements from the end user , the clients and the stakeholders about what they want to see included in the application. This is where we should be able to identify the needs of every part . The difference between waterfall and agile here though is that if the client’s specifications do change… well we have to stop everything , whereas agile can be alerted of this quite early and mitigate the amount of work which needs to be redone.
- Designing. Now we can begin to draw up our blueprints, what sort of tools we need for the job , are we going to use the cloud or host it ourselves, if we’re making a web application how many URLs do we need, what sort of content goes on each page?
- Implementation. What languages are using, what libraries , are we using AWS or Google Cloud?
- Testing and verification. Check the functionality, and see if the checklist of requirements has been met as best as possible.
- Support and maintenance. Documentation for other developers, customer support for consumers.
So waterfall would do all this sequentially … which can be good for projects where the requirements won’t change, for more concrete industries I guess. It is rare that a phase has to be gone back to, and the only consolation would be during the testing and verification phase, where we run our vulnerability scans, static and dynamic code analysis etc. Then we would most likely have to go back to implementation and possibly even to design depending on the issue, and then we have to go back and see if this aligns with requirements. Software development is a naturally inclusive process, and each stage is tightly bound with every other stage in all sorts of ways, and because of this agile can jump over a lot more hurdles in production.
These sorts of issues would be found on a per-feature basis in agile, and development is done based on the functionality of the application. As development goes on we add more and more bits of functionality, checking they don’t break the whole - by testing - and checking they met requirements - by validating. As we have these worked business units, and not a clunky products, we are much more resilient to change and we can become a lot more efficient and responsive to the end user’s needs.
There are two main forms that agile development can take, which are quite similar:
Scrum is a form of agile development that centres around the idea of a sprint. A sprint is like a miniaturised waterfall, where each stage of the waterfall is integrated into single features, or particular functionality of the product. Sprints rely on having the requirements prioritised, so that we know what exactly we shall be sprinting over, and what teams are trying to complete. Requirements will be relayed through each sprint, and the list of all tasks to do is called a backlog. From a security perspective, there is nothing in the scrum model that prevents security requirements being met; however, security requirements and processes should be added to the backlog of each sprint so that each feature has some security considered as part of the design. Here it doesn’t just have to be an afterthought.
Extreme Programming (XP) is another form, which centres on user stories, which architect the main features of a product, and then changes and notes can be added to it to denote at which stage of the development process this user story is on. XP centres on the release of small changes on a regular timescale. It requires a constant communicator between teams, pair programming is quite common here (but not exclusive), as a result of the collaboration security personnel are included when it is time to perform testing, or even during development itself.
Version Control and Change Management
Now to jump out of software methodologies and onto managing the software itself. We will need to keep versions of it, which reflect the changes made , who made the changes and when. Version control is incredibly important as we can now revert back to previous snapshots of the software right before we adding something that turned out to be an issue. If we do a good job of version control, and pipeline it with our code repository , then we should have a complete history of every change ever made to the project, we have all the documentation of the code which is immensely powerful for debugging, stability and clarity.
When developers are working on a feature , and they want to submit it - it shouldn’t go straight through and into the main repo and the version control shouldn’t immediately add it to the history , we need to check it first ! This is what we mean when we say change management - ensuring developers don’t just add their commits whenever they feel like it, stuffing the codebase with God knows what. Typically a lead developer will have the role of “change manager” which just gives the thumbs up to any code that has been put up for submission.
Provisioning and Deprovisioning
These two essentially mean adding a user to a system, or adding an application to a device - depending on the context. In this chapter we focus mainly on the latter, and provisioning in this sense is to do with launching an app on a particular device , or set of devices. So an iOS app for iPhone, iPad etc. We would code our app slightly differently if we were to make it for Apple or Android as the phones have a different way of referencing things like the camera, touchscreen etc. Provisioning is configuring our code properly so it can be added to their respective devices.
Deprovisioning then would be removing the app from that device.
Secure DevOps
DevOps emphasises collaboration between software development professionals and operations professionals (these who deliver code onto web servers, maybe Kubernetes clusters and also monitor the performance of the application, and may redirect traffic to different servers). DevOps teams are the cogs in the agile development wheel, as they allow incremental changes to continuously advance: they are the sifters, the organisers and the conductor.
Secure DevOps refers to the inclusion of certain security ideas and principles which will be included into the Continuous Delivery/Integration pipeline.
Security Automation. Automation is a super skill in DevOps, and what it can do for your pipeline is unbelievable. We can have testing frameworks that watch over the repository and run the core tests which must pass for each new release, this way no new version should be bringing in any major bugs. For example, Circle CI is a tool that’s used by DevOps teams to create their pipeline. It connects to your GitHub project and then you can add on extensions as it sees every new commit, and this can include static code analysis, checking for standard bugs and semantic errors, and even vulnerability scanning (for things like buffer overflows, un-sanitised input fields etc). Such automation as we see with this pipeline can reduce errors, cut checking time , thus improving delivery time etc. Security automation is the use of extensions, scripts or what have you to harden up the code base, to remove the need for manual labour, and for them to reorient their energy into more complex tasks.
Continuous Integration and Continuous Delivery. CI refers to the process of updating the code base and improving the production codebase. Through the use of automation, DevOps can efficiently test, update, and release minor changes to production environments. Since these changes are release in small updates, instead of relying on the deployment of large updates that contain many small changes, errors are less difficult and time-consuming to discover.
Continuous Delivery is the next stage and it essentially automates the re-mounting process of our new codebase onto our webserver for us. If you have used things like Heroku or Microsoft Azure then you probably know what I’m talking about here
Here is a tutorial that covers CI/CD with Microsoft Azure.
Baselining is another good practice, especially for version control, as what it wants to establish is a stable, functioning point that we can bounce back to. This is why you see version jump from 3 to 4 , and not 3 to 3.1 as the jumps are meant to reflect a new baseline. It can also mean the core tests which each new commit must pass, and we can always run baseline checking through security automation. Baselining is what determines the standard set of system functionality and performance. It could mean, for more low-level applications that we want to achieve a certain speed, and new commits cannot jeopardise this speed. If a new commit comes in that manages to optimise a core algorithm, and safely reduces the computational time then we would say that this new becomes the new baseline. This would be a metric-driven baseline that has been improved, but if a commit were to impact these core elements instead, this update has to be withheld until a time it can be released, after fixing etc that don’t impact our standard.
Baselining and version control are integral to systems which are never modified , patched or upgraded and these systems are called immutable systems. In the event the system does need to be modified then the machine needs to be taken out of production and the software is replaced with a completely new system…As long as the core functionality is there, the only time we would really want to update the system is for crucial patches and fixes. If we find problems with the new system, then we can just revert back to the old and functional version , no harm done. If you have ever used a programming language which has immutable data structures, you know then that the structures themselves are never directly modified, but a new one is made with the respective changes.
Infrastructure as Code
To be able to use infrastructure as code in our traditional environment of development servers, production servers etc it means we must define a layer below (which we can then write code to) , which stitches together the code with the configuration necessary to build the environment. The best example of Infrastructure as code is Docker. As developers can write “docker code”, docker configuration files, that build the project again into a running system , and in this case an executable docker image. As developers become more involved with system configuration, it also means DevOps team members can be more involved with the actual development process, aiding in this configuration and maybe even more. This is way better than the older approach of developers writing applications and then shipping them off to operations teams to be made executable, because errors aren’t as black and white as the procedures we have enacted, and usually needs the collaborations of both sides to find a feasible solution to configuration problems, scaling and such.
Now onto the actual coding . Secure coding techniques
First let’s talk secure coding. Any useful application will take in data from the end user … otherwise what’s the point, but we need to sanitise this input , check for malicious code and we need to make sure it is formatted correctly for other functions to use, and for it to go in the DB.
Proper error handling
During an error exception an application should log the incident and record the conditions of the error. We also rely on the programming language in use to spit out a clear and concise error report, showing things like the line number, what was the last function invoked etc. One of the problems with logging and information retainment is where to store it, when it is captured as we don’t want it to be publicly accessible, how easily can a user snoop around and find these diamonds? Do we show the user everything or just throw a generic page that says “It appears I have crashed”. As these reports show function names, file names , and general weaknesses in the program it is important not to disclose all of it, as the technical and curious user will take advantage. If an attacker can figure out the framework, the language , the versions of either, then it is a matter of time before they google something like ASP.NET v.x.x into exploit-db…
Proper Input validation
In web based applications, users can manipulate the inputs to gauge program behaviour. For any entry points in the program, a developer must handle and sanitise these inputs effectively. Input must be validated before being sent to the backend for processing, to mitigate these types of attacks.
- Buffer overflows. This is where a program starts using up more than its allotted memory and starts to spill into other sections of memory. These sections may not have the same tight restrictions like its own memory space, and if an attacker were to then run a script in this free space , it could run with admin privileges.
- XSS attacks. A type of cross site scripting attack is DOM based, which leverages functionalities a user can call in the browser console for example, and then execute their own JS functions that can glean a lot of useful data from the website. This doesn’t even have to be sent to the backend , it can be executed locally :/
- CSRF or XSRF. This is where an authenticated user is sent a malicious link, containing an action inside which will do something like “give me funds please”, and this type of thing is a legitimate action, so it can’t be sanitised any further, and so we rely on our backend system having the right kind of authentication technology that keeps a shorter session with each user, maybe geographically based. Kerberos is a good solution to this problem.
- Injection attacks. SQL injection attacks work by throwing SQL symbols into an input form, and if they don’t escape the string then the characters would be evaluated as SQL characters by the time the data makes it to the DB.
Normalisation
Normalisation of a database refers to organising the tables and columns to reduce redundant data and connections, thus improving overall search time - and hence performance. There are three levels with which we can impose normalisation.
Here is a good guide illustrating the different levels.
Stored Procedures
GraphQL. Essentially , instead of letting users clobber together the requests they want to enact with an input field, how about we remove them all together and just let the user work with precompiled search queries, with which we know to be secure. These pretty much wipe out the idea of SQL injection attacks, as the user is just playing with the functionality of the system.
Code signing
In order to confirm the entity who ships a product to be the actual company, what we can do is sign the codebase, which hashes the entire project and passes it along to the user, who then will do the same thing and check hashes. If the hashes match, then no changes were made and the codebase is in the form it is supposed to be. Code signing is accomplished using a PKI , a Public Key Infrastructure, in which the developer signs the code with their own private key, and we verify that signature by using their public key. For this to work, the key pair should be issued by a recognised certificate authority , otherwise what’s the point it could be anyone.
Encryption
- Include cryptographic libraries to hash things like passwords…
- Don’t try to invent your own algorithms , that’s madness. Use battle-tested ones.
Obfuscation
- This means to hide data and obscure its meaning
- We may obfuscate data elements within development and testing environments, so that the attacker doesn’t get to see what sort of actual data would be processed here.
- Obfuscated code is a disaster, when that guy leaves, who the hell will understand it? Nobody can read it, maintain it or make changes, so you best believe some features will have vulnerabilities, features take longer to make and you’ll soon be outta business.
Code reuse and Dead code
As systems are developed, it’s often more efficient to reuse code from another system that has similar functionalities (use of libraries).
Code reuse simplifies system maintenance as we effectively offshore it to the maintainer of the library. The downside of this though is that failure of vulnerabilities found in this code spread everywhere they’re mentioned.
Dead code is code that once executed , will never produce an output that is actually used in the program, a jut in our pipeline… Unneeded code is just a security risk due to the fact an attacker could invoke it with malicious intent (integer overflow).
Server-side vs Client-side execution and validation
Because we cannot trust any client, all sensitive operations should be done on the backend, away from the client as we can’t ever say for sure that it has been vetted and conforms to what we deem secure, only we know that , so it should only be us that sanitises it.
Client-side input validation can be used to check things like whether the input field has been completed, is it a string etc.
Memory management
For languages that don’t use garbage collection, then buffer overflows become more potent attack vectors as pieces of information stay within application memory. Errors in memory management, poor use of pointers, hanging pointers can all create vulnerabilities that an attacker can exploit. For most program domains, garbage collection is performant enough, rather than tracking it ourselves.
Data Exposure
Data exposure refers to the loss of control over data from a system, most commonly when we deal with highly sensitive information, a disaster would be if a user were to query for their health information, and got all the data from people that had the same name! Also, things like logs which may sit on the client-side may reveal to much data about the program itself, and give the attacker crucial things like application versions, what programming language and version etc. Data at rest, data in transit (is it encrypted?) must all be accounted for.
Code quality and testing
Now we’re at the stage where we assume our code is somewhat functional, it’s time to test it. Before our code has to go into the wider world, where attacks can be thrown at our program just for being online, and being a pivot to the underlying server, the last thing we want to do is show a buggy program to the world, as it only gives an attacker more pathways.
For someone who doesn’t do any testing, and feels like living on the edge, these two repositories of common software vulnerabilities are very useful to know, and they might refer to some of these in the exam, don’t worry I shall cover it all.
- The Top 25 vulnerabilities by MITRE for standard programs
- OWASP Top 10 list for web applications
Code analysis are the processes we run we when want to test the robustness of our own codebase. We look for weaknesses, like simple syntactical problems, and more complicated things like vulnerabilities. Code analysis can be broken down into two forms: static and dynamic.
Static code analysis - Involves running the code without execution. So just looking at the syntax of the code and whether or not we can optimise certain operations. Seeing if any of the code is redundant.
Dynamic code analysis - Is the testing of software whilst in operation, and to do so , any parameters which the program requires are given as test inputs, to see how the program will react. It is designed to produce specific results, and to measure the actual versus the expected results. Fuzzing is a form of dynamic analysis , where a brute force test method is done to detect input validation issues or vulnerabilities of the system, think like clojure.spec.
Both forms of testing benefit greatly from automation, as the automated tools can use be inserted with types of input, types of tests (like input testing, use of really big numbers – think integer overflow).
Stress testing is where we create as many sessions as possible with the application and we push it to the limit to see how much it can handle without breaking. Then, we review where the bottlenecks were , like the I/O parts of the program and other performance variables , and see whether we can optimise these processes in any way. We may typically see a certain amount of traffic on our system at any given time, and testing to make sure the system works under these normal conditions is called load testing. Stress testing is meant to take load testing further, to establish the highest possible load. For example, stress testing is important when a business is very seasonal, or maybe it’s a special time of the year, the epitome of stress testing being black Friday. Load testing defines what we can carry without our “arms” aching, stress testing is how much we can physically left and not die.
Model verification
Now, say we do all these stress tests, and we figure out that the only way we can possibly serve so many clients is to make the website a single page, with hardly any CSS and interaction, do we even call this a proper website? Is this what the user really wanted ? Model verification is where we ensure that our system or application meets the design requirements and the needs of the customer. Model verification is where the verification of our model is done by the customer, an assurance that not only the unit components are working, but the interaction between functions, the latency of our servers are low enough to deliver a concise and useful product.
Difference between compiled code and runtime code
Compiled code is done before the program is actually executed, and hence compiling code produces an executable. Compilation is the process of taking our codebase and adding whatever libraries and third-party resources we reference and packaging it up into one binary file ready to go. This can be run on any computer, that has the instruction set the compiler used, instantly and compiled products are much faster than runtime applications as this involves churning through the program code each time and as soon as we’re done evaluating one section we execute it and move onto the next function. This is what languages like Python and Ruby do, they run their script file through an interpreter , which makes use of the program space the OS allotted it , and then we translate everything starting with main and all functions it references. There is no executable file, which is cleaner and its a simpler life , though one I wouldn’t use for production of time-sensitive applications.
3.7 Cloud and Virtualisation concepts
The cloud and virtualisation have both been interesting ideas of how to use hardware, and what the combination of resources and networking can take us. The cloud centres around the idea that one company can setup the data centres, the security, code the login portal , allocate resources as clients may need, and all the requirements on their end is to connect through to this account with a working internet connection. The cloud nowadays houses many client web applications, tons and tons of corporate and consumer data. Corporate data isn’t always a good idea, and really should be kept private, but some do use it for storing their encrypted credentials.
Virtualisation centres on the idea of maximising client resources, and that we can partition our hard drive, under the management of a hypervisor (for Windows OSs) and use each allocated space for other operating systems. We might want to do this to test how well our apps work on different platforms, to separate our “main OS” from this new system which we can test the venom of different malware on etc.
The cloud
People can use other corporation’s resources in the same way they would use their own, but to the fact that the provider can scale their resources, and they have such a wealth of computer power at their fingertips , it takes them into another league. It smooths out a lot of otherwise rusty and tedious business functions, like backups. Cloud storage is a service model where data is stored on remote servers that are available from the internet. The benefit of this is that the cost of our own upkeep , maintaining servers, paying people to do backups, not to mention all the space that’s taken up is replaced with (depending on your amount) a rather modest monthly payment. The only downside really is that if there is an incident where the data centres flood, or crash of whatever, the data may be lost, or the data might be compromised by an attacker.
These massive servers owned by companies like Google, Microsoft use virtualisation techniques, so as to allocate space to each client on one machine, as one’s needs may be greater than others, and so custom environments are created. The servers with which clients make access to aren’t always the same on, and they may be spread over many geographical locations, the data itself is reserved on a single machine, but other functions like portal login are more variable.
There are three different ways to setup repositories - and they differ really by distance and who is doing the upkeep…
The first , and nearest , is on-premise. This is where the company owns the hardware, operates on them and configures everything and does the job of maintaining it. This certainly isn’t a cloud, as we have to do all the work ourselves and benefits of the cloud like off-shoring doesn’t apply here.
Hosted is the grey area , as we are using the resources of other companies, but we may or may not know where the servers are being hosted and it is unclear how much of the work we have to do ourselves, but it is in the middle between complete ownership and complete deference.
Cloud is where we allow a third party , like Google , will do all the work for us - setting up the servers and setting aside a portion of the hardware for us. Everything we would do on-premise is now done by them , all that’s left for us to do is to configure it the way we want and add our applications, or operating systems on there. How much we need , and how much we can happily let Google configure is to do with the different cloud deployment models on offer.
Cloud deployment models
Software as a service (SaaS). This is the offering of software to end users from within the cloud. Rather than being installed on client machines, just by being authenticated to a given cloud server, you have access to (in the case of the google suite) access to Google Docs, Google Spreadsheets , which are all Software as a Service. The only trick here is that the service has no payment as exchange, data is worth its weight in gold.
So software is just access to an application through a browser or whatever medium to the cloud. What would a Platform as a Service (PaaS) be? Essentially its just the composition of a number of applications on the cloud with which are now at the fingertips of end users. So for example, Facebook has a number of extensions and applications - Facebook Dating , Facebook Marketplace etc. These are all applications , albeit sub-applications, but nonetheless more functionality given to the user through the Facebook platform. So it’s a layer deeper into the cloud, where you have access to Facebook’s API for making web applications, and you are given things like database access, for other PaaS where the access medium is a desktop app, you would then probably be given an Operating System with which you test applications on. For example, the platform which I use to get better at Penetration Testing is called tryhackme.com and then offer people who subscribe a Kali VM through their cloud (web server) and they manage your OS, they let you develop your own scripts there, run your own stuff and browse on the web. That is probably the most powerful PaaS , when the provider gives you your own application stack.
And lastly, if you haven’t already dozed off, I’ll explain Infrastructure as a Service (IaaS). This is where your access goes yet deeper and you can practically touch the bare metal itself. The provider just gives you the hardware and the application to access said hardware. The user is responsible for putting their own Operating System on it, configuring the OS and from there installing all the applications they want. It becomes more general as you attain more power. An example of this would probably be AWS.
To summarise , with SaaS you’re responsible for your activities on the application they give you, with PaaS you are responsible for making the application - with the modules they give you and for IaaS, you are responsible for maintaining the Operating Systems , which allows you to build your own custom applications , which you must use responsibly. So the amount of consumer involvement rises with each level.
Types of cloud provision
There are many different ways that corporations lease access to the cloud, from anywhere between full public access, to total restriction down to just a single user.
The private cloud is the most common model business take up as it gives them the chance to apply security controls and have a degree of strictness that otherwise wouldn’t be achieved on something like a public cloud. Now public cloud doesn’t mean the data is public, and hence easily retrievable, but the general public can access their infrastructure (so something like Dropbox) , their little slice of the cloud but due to their desire to be public, you can’t really enforce something like an Access Control List - moreover these different cloud provisions are like ACL strengths.
A community cloud is one where people or organisations who share a certain interest, belong in a certain IP range or what have you share an environment. Remember the extranet we talked about way back? This could be the system which gets shared between companies, aside from their own internal networks and sort of becomes this intermediary for experimentation. With things like IaaS , not so much PaaS even though you’re given an OS to install the virtualisation software, but you wouldn’t be able to do things like disable secure boot and enable virtualisation technology. You could give it a try and see if it’s supported though.
A hybrid cloud structure is one that combines elements of these listed above, and may have private access if you supply certain credentials, but otherwise has public access, that kind of cloud structure. Hybrid clouds could be also be completely public , though you need the right credentials to access the private infrastructure below, and start logging into the kiosk machine. This is what I do when I log into tryhackme.com and then I can access the VM for my account.
Security as a Service
So far we’ve covered the outsourcing of hardware, but what about outsourcing our security? Surely , if our applications go on the cloud we need to then have our security testing be on the cloud ? Makes sense. Testing of our platform and its applications can then be outsourced to a vendor who has the resources, scale and speed to give us a quality we probably couldn’t achieve ourselves. This vendor is called a Managed Security Service Provider (MSSP). MSSPs hire security experts in their realm, to run specialist tests that a user may require, like email security or incident response service. Cloud access security brokers (CASBs) is a piece of software which is configured to be in the middle of the cloud network and the organisation’s private network. It checks the traffic coming from and going to the cloud , and monitors it to see if they are abiding the agreed security policies. It will also check to see that the data stored in the cloud is encrypted. As this sort of measure is quite extreme, and I wonder why someone who would want such security upkeep would consider the cloud anyway… Maybe it’s still cheaper this way, but costs shouldn’t be priority in such an industry like healthcare of finance which would inevitably need a Cloud access security broker to enforce some policy. Most MSSPs who do offer the aforementioned services also provide legal declaration of adherence to whatever policy applies to the user.
Virtualisation concepts
Right this is going to be a little sidenote on the whole cloud thing, as PaaS and IaaS both use virtualisation technologies to partition not only their own resources, but the provider will also use virtualisation on the bare-metal server , which has no OS and is called a Type I hypervisor which will allocate resources to all virtual machines which are created on top, and which clients will access (if it is a PaaS, if it was an IaaS they would be able to choose what OS and how much space they were allocated). A type II hypervisor is one which sits atop an Operating System and it then allows virtual machines , which also sit on the host OS itself.
Hypervisors are low-level programs which separate a computer’s OS and applications from the underlying hardware. The hypervisor is responsible for allocating resources to the virtual machines VMs.
Virtualisation can be incredibly useful as a hypervisor could store the VMs for all the different employees, and then we would only need one server, not all these computers and laptops we would have to buy, but since the activities are done on a machine that we can monitor, theoretically it should mean the employee can connect using any device and the corresponding credentials. When we put a user’s desktop onto a VM , this is called a Virtual Desktop Environment (VDE)/Virtual Desktop Infrastructure (VDI). When creating our corporate infrastructure in this virtualised style, we want to think about whether we want the sessions on these Virtual desktops to persist after they shut down the VM , or to be non-persistent and wiped back to a baseline state afterwards - this being the master image that is installed on the hypervisor. Depending on the task will determine whether or not we want the user to build up a profile on the VDI/VDE.
As virtual machines are just files, we can store quite a few employees entire workstation within a single folder. A benefit of this is that if the server itself crashes, if we have the folder we can just move it onto a different piece of hardware, install the hypervisor and we can be up and ready to work again in minutes. If we have backups of the files, it makes maintenance and fixing of the server easier as we can reset things, then pop the folder back on and we’re functional again. Our hypervisor can watch over However whilst this presents all sorts of conveniences , it can also be incredibly dangerous as an employee could just copy that folder, and he essentially has the accounts of all the staff which he can brute-force at home.
Applications cells and containers
Application cells more commonly known as containers offer the same sort of functionality as virtual machines, as it stems from the same idea of resource allocation and isolation - only the VM will have resources allocated , and on top will sit an OS and then the programs; however, with a container (less commonly cited as an application cell) instead of running an OS there will only be portions of an OS , the programs built-in tools which the program needs to compile and become useful. It won’t have the kernel, as this will be shared between every container, just the modules that the applications needs and then whatever defaults the kernel below has. Keep in mind though that only the kernel code is included for each application, but applications don’t share resources, files and such. This is very efficient as applications can share a single kernel, and these snapshots can be tested thoroughly, with less space needed and with such fine grained control they have the ability to be heavily optimised.
VM Sprawl Avoidance
VM sprawl occurs when the number of virtual machines reaches a point where the administrator can no longer effectively manage them, and their current method of managing all the resources essentially fails. Stricter policies would have forced the admin to close down VMs that are no longer in use, instead of letting them linger, and logging the activities of each machine to understand what each one does. The natural tendency though is not to interrupt running environments, so maybe policies should be put in place at startup to include logging. As VMs are essentially large files, it is quite easy to spin up a lot of them, and hence lose track of them in large, and complicated dev environments. The worst case scenario would be a system admin that keeps an old VM running, which also has network access and thus compromises the machine to an attacker who makes it in the network. We can stop this from ever happening though with regular user auditing and reviews.
VM Escape Protection
So now that an attacker has compromised a VM, it isn’t long before the host OS is done for. As these systems use the same memory , processors etc it is plausible for instructions to slip down into these layers. Due to these host OSs generally housing multiple VMs, this would allow attackers to pivot from one system to another pretty quickly. Most VM technologies come with some built-in escape protection, but understand that organisations should treat VMs as any other physical system.
The same intrusion detection and prevention principles of logging, proper file permissions etc should be employed.
3.8 Reducing risks through resiliency and automation
Managing server hardware
Now, the end goal of this is to maximise the time we are live and public facing. We have to use every trick in the book to ensure that our business is live, no matter if the servers break , the site explodes or equipment breaks we may have a plan to stay online.
There are many terms, which pretty much all mean the same thing - but the exam is going to ask you about the nuances of these terms so I shall try my best. The first is redundancy. This is where we plan for computers, subsystems and network failure by keeping a stock of spare parts, spare servers even in the event of a crash. The different types of redundancies include:
- Disk redundancies. Using backups and extra disks - making use of RAID and a given RAID spec.
- Server redundancies. Here we would use failover clusters , and manage them with a load balancer.
- Power redundancies. Making use of an Uninterruptible Power Supply (UPS).
- Site redundancies by adding hot , warm or cold sites.
Redundancy is to do with the upkeep at the device level, so individual servers that are high impact and of high value, critical network components that may overloaded and fail should really have a redundant part . Whereas Fault tolerance is to do with the redundancy of the entire system. So that last bullet point would be total network fault tolerance essentially. This is where we plan for a level of redundancy at the network level and in the event our network collapses there should be another site where we could visit and establish a connection.
And the last similar term we have to know is high availability. This is where we expect a system to be constantly accessible , utilising as many different redundancy and fault tolerance methods as possible to achieve this. You often hear of the five-nines reliability , and this is to do with the 99.999 % uptime of the system - which translates to about 5 minutes downtime per year. The general rule is that if all the redundancy and fault tolerance measures are less than the cost of being down, invest in uptime.
Like I mentioned, we use the methods already known to us from the first two methodologies :
- Failover clusters for high availability. This is where we have multiple servers, nodes, and if one of them crashes we can pass traffic through to the other(s). All nodes have access to shared storage, and they run diagnostic checks on each other to check their respective status.
- Load balancers for high availability. This is where a piece of hardware of software watches over servers and directs data loads across computers , so if one gets overloaded you can begin to direct traffic to others and you can increase scalability this way, as we are in a position to serve more clients.
- Distributive allocation builds on the same idea, to garner high availability and scalability - but it is more to do with issuing resources to all nodes and separate tasks between those nodes. It is most often used in scientific applications to solve complex calculations. It allows for scalability as we can always add on a node, and it will be assigned a task - and there is high availability due to the fact we can handle a single failure.
Now onto scalability and elasticity. The difference between the two is slight , but the former is all to do with becoming more efficient , having more and more servers and becoming more optimised , whereas the latter is all to do with the way we can add and take away computing power (hence elastic) whereas scalability is to do with the growing empire of computing power.
Managing server software
Now that we are aware of the tricks to secure our hardware and to make our infrastructure more fault tolerant , and hence highly available , let’s look at managing what is actually on this hardware - so the Operating Systems and how they configured and all applications which are installed.
As our systems fail and we need to start up a new server , it would be a nightmare if we had to configure a secure operating system each time - making sure we had the right configurations … then we could hardly say we were being efficient. We need a way that we can reuse the secure settings we define , say in a secure OS and then pass it on to new systems. All the configurations , files and settings we have on a secure system can be captured into a master image, which would be the snapshot of that system which we deploy to all other systems. We can do this for employee computers, but this is called the baseline - as we then add the unique features on top for that particular group. With the master image, we configure a lot less after deployment , as that server is meant to be a replica. The things we would change would just be things to do with IP addressing, firewall rules and IP tables.
Templates
Aside from reusing configurations for servers, we may have to reuse configurations for applications and services - like web servers and database servers. This is where templates come in, and they are basically an image for applications and the like. Again we don’t want to configure by hand the same thing everywhere, and it is likely that a master image will make use of these templates to quicken installation.
Common things we want to template is the web server we may use, and its configuration, other applications like Docker which have more complicated settings definitely should be a template (as much as possible).
Non-persistence
Non-persistence will use these master images as the baseline and they may return to once the session ends and the computer shuts down, hence this would be a non-persistent system which reverts back to its known configuration. This is how live boot operating systems usually work, they don’t let you do anything substantive and all files saved are just in a /tmp folder and lost when you turn off.
The specificity of our templates can be much greater if we know that we will always revert back to them after a session with that application is over - as there isn’t anything for the user to preserve or do outside of it.
We may fallback to a previous snapshot, which is entirely different specification , or we may revert a particular application back to a previous configuration…
Resiliency and Automation
Due to the wealth of reusable components we have, automation can pull from this and script the installation of new servers, employee computers etc. The more we define and articulate into code and file - the easier it can be automated. Moreover , this makes the server itself more resilient to attack as these images and templates have been battle-hardened and tested by administrators and technicians. We don’t have to compromise on quality as we start to scale.
Whilst we can automate all this, we need to make sure that what we have installed is doing the right job, so we would do the following:
- Continuous monitoring. Seeing the servers we have gotten up and running are working the way we expect , by conducting vulnerability assessments, risk and threat assessments. We can have a SIEM pair up with this tool and the reports it receives from the servers are logged - and alerts flare up if anything looks wrong.
- Configuration validation. Ensure the templates we have installed , say with the latest patches , are present on the server. This is usually in force on corporate networks when we want to check that an employee has configured their work PC in a way that doesn’t leave it compromised.
- Automated courses of action , used in assembly lines, to redirect traffic, how do we respond when a particular unit goes down?
Redundant Array of Inexpensive Disks (RAID)
Takes data that is normally stored on a single disk and spreads it amongst other disks. Similar to distributive allocations only the difference is RAID replicates data, DA replicates information, but each allocated unit is also in use. RAID is just a backup. The purpose of RAID is to act as a recovery unit if any single disk is lost .
Two RAID formats are:
- Striping - spreading and storing the data across multiple disks.
- Mirroring - process of copying the data from one disk to another disk(s). This is where each bit of information comes from one disk and then all of the info there is then pushed onto others. Not as dynamic as striping.
RAID Levels

RAID 0 - Striped disks. This is where we take our data , divide it into blocks and write some of the blocks to one disk and the other blocks to the other disk. These writes are done simultaneously, though if one of our disks becomes corrupted, it means the other loses all its redundant attributes and becomes unusable as well.
RAID 1 - Mirrored disks. This is where we take our data, divide it into blocks and write each one to both disks, so after each backup the disks should look identical. Now whilst this is more expensive, as the drives themselves will have to be large (as if we were doing all our backing up on a single drive…) it does mean our operations are saved if one corrupts though.
RAID 2 - Striped disks, with bit level writes instead of block level. So instead of writing blocks across multiple disks, it is a lot more granular, and another disk (apart from the two seen in RAID 0 for striping) is for the error correcting codes. Moreover, if either of the “data” disks were to crash, than we can use this third disk to mitigate this and we can survive.
RAID 3 -Striped disks, with byte level writes spread across multiple disks. Similar to RAID 2, but it uses a separate drive for the error-correcting codes and checksums for all other data disks, rather than RAID 2 which can have as many parity drives as it does data drives. RAID 3 also has a minimum of three disks, but the small differences, due to the marginally higher write speeds have meant that this standard has become obsolete like the last level.
RAID 4 - Essentially just the use of a dedicated parity drive for the several striped disks.
RAID 5 - Stripes data and parity checks across multiple drives.
RAID 6 - Double parity or level 5 with an additional parity stripe. This allows the volume to continue when two disks have been lost.
RAID 10 (or 1 + 0) - This is where stripping and mirroring combine, as we can see the mirroring affect as we have two disks, which represents a degree of redundancy, but also we have the striping affect as we have written separated the blocks of data into two different sections.

RAID and Windows
Windows has a built-in capability to set up a software RAID (Redundant Array of Inexpensive Disks) that combines multiple disk drive components into a single logical unit for purpose of providing fault tolerance or enhance the performance of your storage subsystem. Based on the various formats used for storing data on the disk-groups, the RAIDs can be of many types, the common ones supported by Windows are RAID-5, RAID-1, and RAID-0.
Software RAID, unlike its hardware counterpart, is slower and entirely dependent on the operating system. Therefore, if Windows becomes inoperable, the only way that you can access your data hosted in a software-based RAID system is by restoring Windows and ensuring that RAID disks are all intact.
3.9 Physical Controls
Physical controls are those which are essentially compensating controls for the lack of protection inherent in computer hardware, and the threat of criminals who could come on site and steal resources.
The first and most important thing is lighting. Without it, there is no point setting up cameras, unless you’ve got infrared, but allowing security guards to monitor areas and observe activities in otherwise pitch-black areas reduces the “working space” for criminals. Angles of lighting , and the strength of lighting are crucial things to think about - so we can capture the faces of people in that area , as we presuppose it to be area where people shouldn’t be.
For the genuine employee, or clumsy individual or walks into an area they are not supposed to be in, we should provide signs for them to keep them on the right path, and demarcates where regular access stops, but senior staff access continues. Signs tell visitors when they are prohibited to enter and moreover this can help with enforcing a form of punishment for when they do abscond from these rules.
Alarms are equally important, as they alert us when something happens outside of normal conditions. However, alarms are only useful if they are acted upon. Facilities that have too many alarms, may generate too many false positives and hence we may get complacent as the value of the alarms goes down. We must make sure alarms are properly tuned and setup in critical locations, so they provide actionable information.
There are three main types of alarm:
- Circuit-based alarms. These need a trigger to go off, so if someone opens a particular door after hours then the alarm would trigger as it assumes an intruder. These sorts of alarms are good on the perimeter of the building as we can deter the attacker from the get-go. If we put this in the server room then the time it took for them to get in could’ve been used to trigger the local police.
- Motion detectors are useful in areas where you wouldn’t expect any traffic, so some museum exhibits have this running all day within certain bigger, more precious artefacts, but when the museum is closed for the day then they would turn it on as they don’t expect anyone to be walking around. Most motion sensors are infrared technology and can detect heat patterns of a person moving. In most environments , motion detectors are used to activate cameras, so when the museum opens up again, they don’t record the pitch black all night and when someone is detected on the motion cameras, they startup so as to try and see if they can identify this individual…
- Duress alarms. These can be activated by people if they feel under threat, so the bank clerk can set this off if there is a bank robbery going on.
Barricades should be used to prevent access from unauthorised parties. Walls , fences , gates and doors are all forms of barricades. Barricades are used all over the property internally, as well as externally where you will see any combination of fencing, walls and/or gates. Doors partition rooms which management sets an access permission onto, and the doors themselves may be configured with a different level of security to others. The janitor’s closet isn’t gonna have biometric authentication now is it… but the server room definitely would, and there might be a short time period where any employee is even allowed in there. Other internal partitioners apart from doors are cages, and this is the internal use of fencing, which you meant see in impound parking lots, where they have fencing around each car. Access to one of these cars is permitted by unlocking the gate, which is what cages use to control flow. Moreover we may the use of fencing in server rooms to to delimit people from having immediate access to them.
More on impound lots, to stop vehicles from going down particular lanes, security can setup a bollard, which is just a small, but sturdy , 3 ft post which is mounted into the ground to control vehicle flow. People can easily walk through them though, and past a bollard is typically a courtyard, reception etc.
Security guards provide visible presence, and are directly responsible for securing a facility. Guards typically monitor entry and exit points and maintain logs of individuals who have entered and exited the building. People who enter a building may be followed, and so what we can do is have a system where we have two layers of doors, both of which require authentication of an employee, but the second one is at the end of a room which is heavily surveilled and monitored and it is at this point where anybody sneaky enough to piggy-back through the first door is trapped. Hence the name for this system is mantrap.
Tokens or cards can be built into badges which are then used to access a facility. These tokens/cards offer the same functionality as keys, yet can be remotely updated to manage access in near real-time.
Protecting the transmissions and communications between devices
Depending on the organisation, they might need to ensure that the cabling they run between systems, or departments is not subject to electromagnetic interference, or indeed human interference; metal tubing might encase the wires or indeed a cement tunnel that cables are then ran through.
We’ve discussed an air gap before, and how it is good practice to establish one, and to immunise the corporate network from far-off wireless attacks. A very strong air-gap could only be breached via physical attacks, as an attacker would never be given access to the IPs of routers, clients as they opted out of the internet…
Going back to the idea of cages now, Faraday cages are those which are usually room sized and encase a room in conductive material, so any external EMI is then circulated and forced through into the grounding wire. This then preserves the flows of systems within the cage.
TEMPEST (Telecommunications Electronics Materials Protected from Emanating Spurious Transmissions) is the Department of Defence (DOD) specification to keep these emissions within the facility, as the dual nature of a Faraday cage is like a flask, prevent exposure from the outside world, and maintain the emissions within the encasing. When signals are prevented from going out of the cage, it makes eavesdropping practically zero.
Slightly off tangent now, but if we are working on our laptop and we don’t want people to be able to see what we’re working on - we don’t want to transmit our work per se - then we can put a screen filter on our laptop. This is where only the person sitting directly in front of the laptop can see the contents of it.
Cameras and logging
CCTV cameras are so useful for detecting intruders, and other security risks (recording server rooms). Today we see the widespread use of CCTV, at least where I live in London anyways, and companies who do hoard such devices have began to connect them into a monitoring network, with each camera becoming IP-based and more easily accessible; however, as with anything that becomes wireless , and without the strong overarching security measures in place, these cameras are susceptible to being cracked open. These cameras should be placed on their own separate network to apply physical separation from the corporate network. Maybe we have an office for security guards that has its router, cabling and such with which they can watch the cameras.
Logs should be kept of all abnormal activity. Physical security records should be logged, such as visitors arriving and departing , invoices being received and shipped off, what goods / services have been done today etc. These logs are useful to see where exactly we went off course. To catch glitches we have to be watching the mundane most of the time…
Secure Storage
Safes often secure storage for those items that require a higher level of protection. Safes are meant to safeguard contained items from fire, floods.
There may be times when utilising a safe is unnecessary, but we still need somewhere to maintain assets securely. Secure cabinets or enclosures allow us to protect these assets from physical threats, such as theft.
Locks are a ubiquitous security measure, and are an easy way to overlay a means of security onto standard draws, cupboards etc. One common use is to lock up a laptop in a desk drawer when not in use.
One particular type of key you should know about for the exam is a bump key. This key is cut with the notches at maximum depth, so that when it’s inserted into a lock and struck, it should have enough height on it to dislodge the lock pin on the shear line and undo the lock - though most high-security facilities have locks which defend against this , by putting the notches slightly to the side, or even re-moving the shear line completely.

Environmental Controls
Maintaining facility temperatures is also important , especially those of a data center. Ensuring we continue to maintain our HVAC (Heating, Ventilating, and Air Conditioning) systems are crucial.
Hot and cold aisles are one method to help control temperature of equipment in data centres. Equipment is arranged so that intake fans face one way, and the current is blow out towards the other direction. By turning these aisles into separate rooms, through the use of blocking plates, we ensure we never mix hot and cold air as the direction have been done in opposing angles, and their circulation has been steered away from each other, to make cooling easier.
Fire suppression systems are designed to protect against the spreading of a fire. These are automatic systems designed to discharge when a fire is detected. They don’t prevent fires but help to mitigate the damage done i.e sensors which set off sprinklers.
Now it is tedious, but you must remember this hierarchy of fire damage, going from most common to most rare and most disastrous. The class D fire , of flammable metal fires is very rare, as metals have to be boiling hot to catch fire and so the traditional fire extinguisher only covers ABC , as D is too ferocious.

Locks
The first type of lock we shall be looking at is the use of hardware locks. These are the standard locks we employ on things like doors in the home and if we don’t have the resources to employ actual security systems then we shall make use of this; however, regardless of the budget of the company , hardware locks are a great addition , a staple , to securing server rooms - even if we have surveillance and security guards.
Something we have to keep in the back of our minds is the fact that the keys themselves must be kept secure, otherwise anyone could gain physical access. Proper key management may include putting them in a secure room , protected by biometrics to recognise authorised personnel, or in a safe.
The next type of locks are cable locks. These are locks which are fitted on laptops in places like public libraries , schools etc. Sort of like this:

If you tried to steal this laptop , since the lock is tied down to the desk, or some other storage unit you would most likely break the laptop. Unless you are a student or member of staff you shouldn’t be able to unlock it. Though this doesn’t stop insiders, and students may decide they quite like the laptop, so they could unlock and then take it home , so it’s not job done.
The last type of lock is the locking cabinets. These are for use in server rooms and they are to lock cabinets that keep a single server its corresponding network equipment, this way an attacker will have a much harder time getting to the hardware itself . Locking cabinets work for servers in the same a file cabinet works for a set of files.
Protected Distribution System (PDS)
Apart from protecting the physical servers, we also need to protect the cabling that connects to them. What an attacker can do , if they find the cables accessible , is cut them and insert an RJ-45 connector on each and link them up to an adapter - and feed these adapter through to a hub. And with the aid of a protocol analyser we can see every packet coming through. To defend against this , technicians and admins can either use a cable trough , which is a long metal container which we pipe cables through , or we can pipe through a false ceiling. This second solution though risks the signals being corrupted by other EMI sources , like lights , so if you can spare the cash get a cable trough.
A trough can stop the use of a physical tap (an unauthorised tap) and so there shouldn’t be any data leakage.
We can mitigate EMI/EMP by using STP (Shielded-twisted-pair) cables like CAT5e or CAT6 cables, as their metal coat adds a layer of resistance.