CompTIA Security+ Chapter 4: Identity and Access Management
Table of contents
| Sections |
|---|
| 4.1 Identity and access management concepts |
| 4.2 Installation and Configuration of Identity and Access Services |
| 4.3 Identity and Access Management Controls |
| 4.4 Common Account Management Practices |
4.1 Identity and access management concepts
There are quite a few ways we can identify, authenticate and authorise people , and for the Security+ exam it will be important to compare and contrast the different methods.
Identification, Authentication , Authorisation and Accounting (IAAA)
For a system to ultimately take into account of its user activities and to build a profile of users on its system like a payroll system, active directory server who knows, we need to start by allowing users to identify themselves. Otherwise we can’t add, we can’t apply any logic to something that isn’t defined, so we allow a prospective user to setup a username, password, and other unique information that we can record.
The next then would be to verify that identity - to authenticate this person each time they log in, all we’re doing is aligning the details stored with the details given at this point. The aligning of credentials should be done in such a way that only the actual user could present all this information. Things like fingerprints, with a Two Factor Authentication Code would mean it is highly unlikely that someone could spoof all this, and with confidence we say that the user identity checks out. If the alignment is simple, and not unique to the person themselves, like a username and password, then an attacker can guess and crack their way through, all the while the system would believe to have authenticated the actual employee.
A more complicated and tedious procedure is to figure out whether this account that we have verified belongs to someone we have at the company, is eligible to perform this action, to look at these files or to execute this program. Whether they are or not will be determined by whatever authorisation algorithm we employ. Once someone has slipped into their account, which presumably belongs to some group like the Accounting department, have they got the right permissions (power) that the group should have? Configuring groups and users correctly is where we may have unauthorised actions, though did they try it on purpose, or what it us being architecturally sloppy?
Now, then up to this point we have a nice flowing system we users can join, perform actions and their access should be controlled. But it is all happening without our knowledge, there is no way I can tell who has done what, and this may be important to detect anomalous behaviour, flaws in our system or if a user were to report an error we would have no idea how to diagnose that problem. All this is the last and most pertinent to the business, the act of Accounting. Taking logs of user actions, seeing by user ID , time and location , seeing the logs of the system itself and what programs are struggling to operate etc. Going back to chapter one, if we were to learn that there was an insider threat, then we would be on high alert trying to see what actions have been done on the system, but if we don’t have any accounting in place, then we can never accuse or prosecute this employee without the needed evidence.
The commands, time of logins etc can all be audited, and the sequencing of this evidence (to build up an idea of activity over a week for example) would be called the audit trail.
Let’s look at the typical login portal and deduce the IAAA structure. When we see the typical:
Username :
Password :
The username is what identifies us, as people could have the same password (though I hope not), but this unique ID is what is supposed to make us stand out, and hence identifiable. The password is what authenticates us, as it is information only we are supposed to know.
Multifactor Authentication
This is what I glossed over earlier, but this just means any combination of unique information that an individual can compose to give a profile of themselves, a profile which can be checked against the system logs and thus verified. We currently have just TFA , which is Two Factor Authentication, so you’ll enter your username and password in , which is one layer, and then you will be emailed, or texted a verification code which you enter on top - this is what should exclude most script kiddies, and what are the chances of a high-level hacker having to come after you? Obviously the more we integrate the harder it is to differentiate us from anyone else, but to do so without it being long, arduous and tedious is another story. It would be great if we could have our computers scan our eyeballs and fingerprints, with our lanyard being scanned by a card reader at the same time. This would be tough to forge and instant.
The categories of authentication include:
- Something you are - The Biometric layer
- Something you know - The Personal information layer , password(s) , Personal Identification info like Mother’s maiden name, first Dog’s name etc
- Somewhere you are - The Geographic layer, does this employee always log in from their office computer in Alabama (as they should) , or are they now logging in from China?
- Something you do - The Personality layer - much like a personal layer, but this can change, though it is more to do with your style i.e. your signature , or even the speed at which you type.
- Something you have - The Corporate information layer , tokens , lanyards , keys etc
I shall talk more about the something you have layer, as corporations can use a variety of ways to authenticate you. The first thing I’ll talk about are smart cards, which are things like credit cards, or clearance cards, that you would swipe across a card reader , and it would let you into a server farm, or aeroplane hanger etc. These cards come with an embedded microchip, which stores your private information on it, and encrypts it before sending it off to the reader. We also have an embedded certificate stored on the card, which has our digital signature (as this is meant to be our card) which lets people know who conducted the transaction, and it can be logged easier.
A Common Access Card (CAC) , is a level above the normal smart card as it includes a photo of the individual , which can be used as a means of authentication to guards, receptionists etc. It is most commonly used in the military to be an additional form of verification. The Personal Identity-Verification (PIV) card does the same job as CAC, just that it tends to be used more in Federal Agencies.
These cards are incredibly powerful as they provide authentication, confidentiality (as your details are encrypted) , integrity (as we give a signature during the transaction, this being hashed, we can see if anything was tampered with during transmission by having the recipient hash the details and then checking the two). Non-repudiation is another benefit, which means that there should be no way that the supposed owner can deny their involvement in the transaction. This is strengthened of course with no factors of authentication, and we could configure the card to have our PIN entered as well when we use it.
Another means of authenticating is with the use of a hardware token or key fob is similar-looking in size and shape to a car key, but it has a little screen on it which has a number that you would use to login to a given service or platform (like an employee portal) alongside your username and password. This number changes every 60 seconds, so it is very difficult to intercept, let alone replay these credentials. This sort of authentication is called a One Time Password (OTP), which gets talked about a bit more in chapter 6. This is a Time-based OTP as varies by minutes , rarely more. It synchronises up with the authentication server, so at each point it changes, the server is synced with the new value. Fobs are the something we have, in addition to the something we know, which would be the password.
You might see in the exam tricky questions which ask you to deduce how many authentication factors a particular device is using - i.e A printer that requires a password and PIN is only one authentication factor, as they are both things you need to know. If there was a password and fingerprint scan, then it would be two-factor , as it is something you are, and something you know.
Single Sign-On and Federation
Single Sign-On refers to a form of authentication where the alignment of our credentials with what is on the system doesn’t just unlock our local system, but other systems are now aware and ready for us to use them. Our credentials have been transferred over, which you may think is a security nightmare , but you have to realise that these systems are usually closed off from the outside world, and they only communicate with the bastion (which is the Single Sign-on computer) and these other units converse with local resources. A good example would be using the a smart door-lock that then unlocks the rest of the house, turns on the lights , heating etc. Another example of SSO would be an employee logging into their portal, which then unlocks the local corporate file-server, maybe Kerberos was sent the details that you submitted and issued you a token to access your files. Now, what I think of as “true” SSO is where the credentials grant access without re-entry and they are used as part of the request, or the systems are unlocked with the initial gate, but either way there is no need for the credentials to re-entered within a single session; however , there is another form of SSO does force a user to re-enter credentials, even though they are the same, into different services. Examples of SSO include using Sign in with Google which are the same credentials that get used for many different services, it also functions well within corporations as we could have an application that acts as the frontend for the HR, payroll, and communications.
Single Sign-On of this style might well use what’s called Federated Identity. This is where an organisation, like Google , or even governments, act as a repository, an accumulation of user credentials that act as the “Identity Provider” and hence can function as a means of implementing SSO, as the credentials are entered, and checked by the IP (usually hashed biometrics, hashed passwords) and if they match access is granted. This way, an employee or consumer would never be entering details to the application, as the application offshores this authentication to the Federation, which then returns - essentially - a true or false.
SSO is to do with how an organisation structures their technological landscape to support granting this style of access, and to the different types of users. Federated Identity Management (FIM) is one way of achieving SSO , though you don’t have to have an external body that verifies , you could do it yourself , and there are SSO styles that do this.
For companies that operate in many countries, across many domains (like insurance, food , sport etc) this can mean a lot of repeated business infrastructure. If we could centralise, but secure, a focal point where we could log and retain employee data, company policies, certificates then this could mean a streamlined infrastructure that gives more power to employees, quicker. With FIM one organisation can grow, and assume the authentication control of many organisations, much like Google sits on top of many a smaller business.
Succint explanation on the two terms above
Article explaining the two as well
Transitive Trust
Authentication through multiple domains is provided through trust relationships. Each domain has its own authentication mechanisms, and if a domain trusts another domain , then it trusts its authentication as well. The trust that a single organisation garners from two partners, should imply that the partners can trust each other as well.
![]()
When one business takes over another though, you may find that the parent company needs authentication access to their branches, however the branches will not have as much power authenticating back to the parent - this would be called one-way trust.
4.2 Installation and Configuration of Identity and Access Services
Identity services are protocols which aim to verify one’s given information, and how this checks out with a given system, whilst access services will use the identity one has provided - with the systems' response - and figure out what resources this entity has access to.
Security Assertion Markup Language (SAML)
SAML is an open standard for exchanging authentication and authorisation information between an identity provider - a Federation like google - and a service provider like Stack Overflow. SAML is an XML based language that provides statements that service providers use to make access-control decisions. Identity providers (an IdP) keep records of users and their respective credentials, so when they a service provider has a request come their way, these credentials are passed to SAML , and then the XML markup for that user is passed along, which should indicate how the server should respond. In this case it’s a great way to setup SSO effectively as it doesn’t force the server to do the thinking of whether to accept or reject.
Lightweight Directory Access Protocol (LDAP)
So X.500 was introduced as a protocol to facilitate directory services implementations, and it defined the specification and operations of a Directory Access Protocol; however, this spec was so detailed, so various and full that it became very difficult to orchestrate over TCP/IP stack, as the functions dipped and dived through the various levels (was designed with OSI model in mind) and so things got streamlined and a core set of functions was released under the protocol LDAP. LDAP was much easier to implement and contains most of the commonly used functionalities.
By directory access, we can mean a few things , which is why there are two different standards for LDAP. Directory access can mean phone directory, which is a record of companies and/or people and their phone numbers. The entities that govern LDAP for telecommunications use is the International Telecommunication Union (ITU) and for internet usage - meaning to govern the access of resources like files , images and videos through the use of an ACL - is the Internet Engineering Task Force (IETF). LDAP isn’t much to gawk out, it just points to a database, where all the good stuff resides, and allows and rejects peoples requests based on supplied credentials. To make LDAP a bit stronger, and to introduce a layer of authorisation and session management, Kerberos can be integrated and tell LDAP whether or not to reject someone, and it grants the user with a ticket to access resources.
LDAP is just the intermediary that strings together DB access, Kerberos, and sits on port 389 usually, though if the communication is wrapped with SSL/TLS then it’s LDAPS which is on port 636.
Kerberos
Kerberos is an authentication mechanism that can help application servers to determine whether or not they should authorise a client’s request. The name Kerberos comes from the Ancient Greek Dog of the Underworld - the three headed Dog called Cerberus , or Kerberos. Kerberos has three points of encryption, and so the name was a nice fit.
Kerberos is a protocol that sits , normally , on port 88 and it takes the job of authentication , that other servers would have to do themselves, and says - “Look, if someone makes a request for a certain resource, give me the Kerberos session key that should be in their request”. If the client hasn’t already notified Kerberos that it wanted to talk to the FTP server, then it won’t have a session key for it, and hence there is no way to get in without one. This is pretty nifty, fast and it allows us to develop our own SSO system, because once someone is authenticated with Kerberos, then we ask to setup a session with whatever server (assuming our connection to Kerberos has been established), and the ticket (the proper term for session key) is given to us. This is what I was on about earlier when I mentioned that LDAP can offshore authentication and authorisation to Kerberos.
Now then, how do we become best pals with Kerberos?
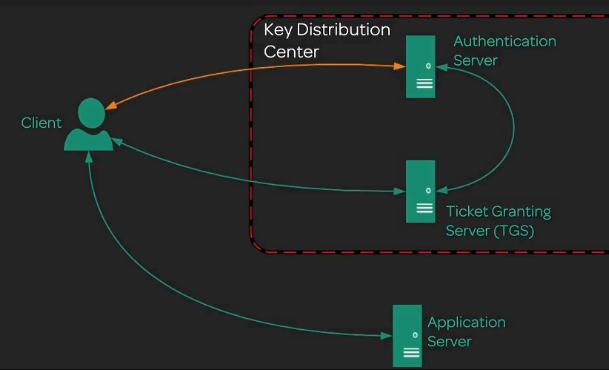
When we make a request to port 88 , which houses this KDC (Key Distribution Centre), we have to enter in our username and password. This password is then hashed and checked against the Authentication Server’s records, and if the hashes align , we are authenticated. Now, depending on the privileges that the admin has set for us on this account , will depend on whether or not we authorised to speak to certain servers.
Now that we can establish a session with Kerberos, we are passed from the Ticket Granting Server, a Ticket Granting Ticket, so when we wish to communicate with someone we pass it back, along with the server name (Principal Server Name is the formal term) and depending on our privileges we may be given a ticket, which we forward to the server with our request. Once the fileserver is handed this ticket, it then passes it to the Authentication server , which makes sure this is within the time-frame, no use of expired tickets, and then sends a back a message saying its fine. This single ticket, a resource ticket , is a momentary session with the server and should last no longer than a day. This ticket can be called a signed token, as it bears important protocol information, and the credentials present on the token (resource ticket) are only good for a single session.
So to round off, Kerberos is primarily a UDP protocol, though it can use TCP for longer , more complicated tickets (if they are require more than one packet) and this sits on port 88 normally. But there are a number of ports that Kerberos needs:
ftp 21/tcp # Kerberos ftp and telnet use the
telnet 23/tcp # default ports
kerberos 88/udp kdc # Kerberos V5 KDC
kerberos 88/tcp kdc # Kerberos V5 KDC
klogin 543/tcp # Kerberos authenticated rlogin
kshell 544/tcp cmd # and remote shell
kerberos-adm 749/tcp # Kerberos 5 admin/changepw
kerberos-adm 749/udp # Kerberos 5 admin/changepw
krb5_prop 754/tcp # Kerberos slave propagation
eklogin 2105/tcp # Kerberos auth. & encrypted rlogin
krb524 4444/tcp # Kerberos 5 to 4 ticket translator
This hasn’t been too technical an explanation, and to know more on how the TGT is encrypted, how resource tickets are encrypted, and what Kerberos requests look like, this is a clear and explanatory video that explains all of that.
Get more detail on this table here
Kerberos resources:
- Kerberos Authentication explained
- [Why would I use Kerberos?]([https://stackoverflow.com/questions/46183178/why-use-kerberos-when-you-can-do-authentication-and-authorization-through-ldap#:~:text=Kerberos%20is%20the%20inside%2Dthe,standard%20single%20sign%2Don%20protocol.&text=Kerberos%20in%20pure%20Microsoft%20Active,look%2Dups%20is%20always%20LDAP.](https://stackoverflow.com/questions/46183178/why-use-kerberos-when-you-can-do-authentication-and-authorization-through-ldap#:~:text=Kerberos is the inside-the,standard single sign-on protocol.&text=Kerberos in pure Microsoft Active,look-ups is always LDAP.))
- Good fundamentals post on Kerberos
- Resource for setting up Kerberos
- Ports Kerberos needs
Remote Authentication Dial-in User Service (RADIUS)
This is another authentication and authorisation idea, and it is one of the most common protocols in use today. Unlike Kerberos, this service also does some accounting functions, logging communications, request details etc to be seen later.
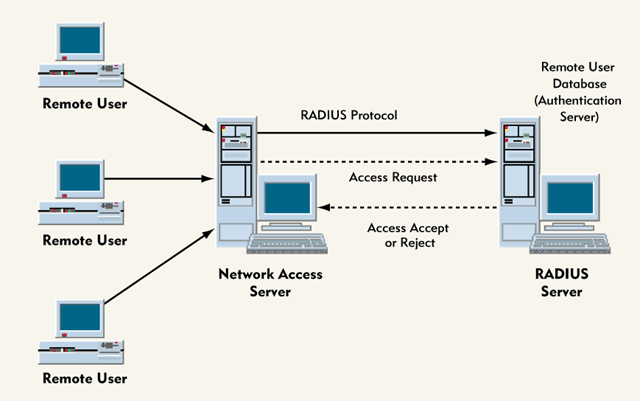
Now the environment which RADIUS works within is quite different to Kerberos, so I’ll start with a little network terminology to clear things up. Within a corporate environment , you have a router which will connect up to the ISP’s router and allow you internet access. More generally speaking this router qualifies as a NAS (Network Access Server), which is the general term for any device that provides access to a remote resource, like a telephone network for example - the reason I bring up the term NAS is because you will see in articles and things about RADIUS that it is used outside of the context of inter-computer networking (the internet). This NAS , router , will take requests from the client, and then forward the packet to the ISP in this case the router would supply credentials to the RADIUS server asking to be authenticated and forwarded to the next server. The RADIUS server runs this authentication and authorisation check on port 1812 and it will return either an Accept , Reject or Challenge message depending on whether the client is known on the databases. In the case of a challenge message, the RADIUS server sends a number that it wants the user to encrypt using the key it should know, and hence blocking out attackers trying to spoof. RADIUS runs the authentication and authorisation checks on port 1812 and then runs the accounting services on port 1813, and will begin to log the packets that came through, with RADIUS throwing them onto that port to be logged. Things such as when the user made a request is logged, and so how long sessions were is kept etc. Operating Systems come with support for this protocol by default, as they do for things like IP and TCP. You would think that with an attacker also having support for it they could then encrypt the challenge, but it is all to do with the keys that have already been agreed upon by NAS and RADIUS… Essentially RADIUS is asking the NAS - “You do know how to do this, right”?
Terminal Access Controller Access Control System (TACACS)
The next form of authentication we shall look it as TACACS, or nowadays known as TACACS+ as Cisco updated the standard, of which this version has been stable since 1993. The services that TACACS+ aims to provide is pretty much the same as RADIUS, and they do the same job which is to provide a means of authentication over a NAS. This protocol uses TCP port 49, and depending on whether you want a connectionless UDP infrastructure, one which caters mostly towards smaller , simpler and faster communications or whether we need a TCP session between the NAS and the Authentication server as there will be a lot of information that we need transferred to and fro before we let people in.
Another difference is that everything is done on port 49, and this is the port used by NAS' when they want to login and become authorised.
Both RADIUS and TACACS+ are authentication and authorisation protocols, so they can be wired to accomplish SSO, as they can both return “accept” packets, which our FTP servers and such can be configured to accept based on what they return.
How TACACS+ actually works isn’t needed for the exam, though you can get a good idea of it [here]([https://www.juniper.net/documentation/en_US/junose15.1/topics/concept/tacacs+-understanding.html#:~:text=The%20TACACS%2B%20protocol%20provides%20detailed,%2C%20authorization%2C%20and%20accounting%20process.&text=TACACS%2B%20uses%20Transmission%20Control%20Protocol,the%20NAS%20and%20the%20process.](https://www.juniper.net/documentation/en_US/junose15.1/topics/concept/tacacs+-understanding.html#:~:text=The TACACS%2B protocol provides detailed,%2C authorization%2C and accounting process.&text=TACACS%2B uses Transmission Control Protocol,the NAS and the process.))
A nice little difference between the two is that TACACS+ will differentiate between user authentication and privileged authentication, and give just one authentication attempt, meaning anymore and it will begin ringing the fire alarm!
Another difference is that RADIUS will only encrypt the password in the authentication packets, when people wish to log into it, whereas TACACS will encrypt the entire authentication process, usernames and all.
For a lot more detail on their differences, this succinct report is great:
Challenge Handshake Authentication Protocol (CHAP)
This idea of challenging the client who wishes to authenticate is taken to the extreme here as the server challenges the client connections it currently has running periodically. It is used to provide authentication over the Point-to-Point Protocol (PPP) , which is a protocol normally for the intercommunication between routers. The reason we want CHAP is to improve the security of our inter-router communications, and if the period check fails then the router can move on and work with other clients, if the transmission is found to be dead then CHAP calls it off. But CHAP is mainly used to suss out any malevolent actors.
The server sends a challenge which is a simple message it wants the client to encrypt. The client encrypts the challenge using a hashing function, and some additional plaintext, acting as the salt, for which was agreed upon in pre-configured settings, or during connection establishment. Both pieces are hashed and given back to the server and this will see whether the client should or shouldn’t have the transmission extended. So it is a three-way handshake: send challenge, send back hash, then reply packet denotes the state of the communications (is it broken or continued…). It is a bit silly though, and I don’t really see why the same sort of challenge would be sent if it is only going to be hashed, the challenges are quite simple … but nevermind.
Another version of CHAP is MSCHAP, which is Microsoft’s version which they released for Windows 2000. It does mutual authentication, trying to authenticate both routers in an exchange.
Password Authentication Protocol (PAP)
PAP is a pretty simple authentication protocol, which uses a two-way handshake - still used for PPP communications and when one router wants to authenticate another. The only problem is that the passwords sent over this channel are in plaintext… which is just open season to an attacker. PAP packets also include no counter or monitoring of the communication, so any captured packets can be replayed at a later date, and so even if encryption was to be used, the encrypted packet can still be forwarded, and access to the router could be handed over.
It is for these two reasons that PAP is a deprecated standard.
OpenID Connect and OAuth
So I’ll try my best to both distinguish between these two and to show you their linkages. Open ID Connect is all about using an Identity Provider (IdP) who can act as the federation (the centralised repository of pre-established user credentials - like Google or Facebook) for the purposes of authenticating , and making it possible to establish an account with a website, which logs you into your dashboard for example, but that account is linked to the IdP. So when you’re logged into Google, you don’t need to log into YouTube, or any product really that has enabled just OpenID connect using Google as it’s IdP. Other products won’t log you in straight away because there is an option of providers to choose from, but the aim is to allow you to authenticate and have a profile , leaving the issue of securing and maintaining credentials for someone else.
To get your app using OpenID Connect, first as the developer you need to make an account which gives the secret OpenID key that you will be sending to the IdP when someone clicks your “Sign in with Google” button. You will create a mini-token which just sends a request effectively saying - Hello, I am an app you recognise and I have an account, could you authenticate this user for me please? And then the user would be redirected to Google or Facebook (if they aren’t already logged into Google or Facebook) and they would be in their dashboard now.
OAuth takes this a step further, and is the framework which authorises users , or resource owners , to perform actions without ever needing to provide a password. OpenID Connect is part of the OAuth standard and they work together to create this flow. The most often seen case is when apps use PayPal to process payment procedures instead of storing payment data themselves. The user logs into PayPal with the OpenID stream, and then the API in the website will call the PayPal API with the actions it wants to perform - so buying a T-Shirt for example. The user is directed to PayPal and they confirm their purchase and it goes through.
Often times you will see - if you log in through Google for example - that a website will want to use the Gmail or Google Docs APIs to perform an action and there will be a popup in the website which says - “xyz application would like to access your Gmail contacts, do you want to allow this action ?” and by clicking yes OAuth will rely this to the resource server - the Gmail server in this case - and the action is performed.
OpenID -> Authentication ,
OAuth -> Authorisation
Shibboleth
Is a service that also provides Single Sign-On , but it does so by being a federated entity for many different authentication mechanisms and it was hoped that it could be plugged into a network that had incompatible authentication and authorisation systems. Although it has been through many reviews, it still hasn’t caught on, as people think of Shibboleth as a patch and an intermediary, not something as clean, centralised and elegant as Kerberos.
Shibboleth uses SAML to log and allow service providers to make their decisions this way, and requests are sent and received to Shibboleth over HTTP post, which may be the reason that it hasn’t seen all too much use, as it limits itself to just web applications.
NTLM (New Technology LAN Manager)
This is a successor to Microsoft’s old LAN Manager (LANMAN) and provides a suite of protocols used to provide authentication to users. It has mostly been replaced by the Kerberos implementation, but NTLM is still used on standalone Windows systems. One of the main weaknesses was that it used the MD4 encrypting algorithm, which has been long since deprecated due to how weak it is.
Institute of Electrical and Electronics Engineers (IEEE) 802.1X
This is an authentication protocol that was designed by the IEEE to tackle port-based security, and it requires users or devices to authenticate when they connect to a specific wireless access point, or to physical ports in a switch with the use of usernames/passwords, or through the use of certificates.
A nice use case of this would be with corporate VLANs. Say your company gets a lot of visitors every week, and they want to be able to use the WiFi whilst there, as we can now specify ports on the switch that belong to employees and admins, and another set of ports which can be used for guests. Moreover we can setup usernames and passwords for that weaker VLAN, and keep our company certificates on the others.
You could implement the 802.1X protocol using a RADIUS server, so as they connect to the router, the packet gets forwarded to the authentication server, and based on the credentials we can either drop it or allow it. Companies often use this for their VPN connections - checking the certificate and then allowing traffic to flow through.
4.3. Identity and Access Management Controls
There are many kinds of access control , ways of controlling the flow of accounts and resources - depending on the strictness of the organisation.
Within the military and governments, you often see an access control management model called Mandatory Access Control (MAC) which assigns users (subjects) and resources (objects - such as files, folders, printers, computers) an immutable permissions level. These classifications have to align any time you want to access a resource, and if you are not at least the same privilege, then your access is denied. Examples of classification levels with MAC Include:
- SECRET
- CONFIDENTIAL
- PROPRIETARY
- PUBLIC
MAC rules can defined in a lattice, with each row mapping to these security levels, with SECRET on the top row , all the way to PUBLIC on the bottom. Like this:
| Government Docs | War plans | Secret services |
|---|---|---|
| Research | Legal Issues | Executive docs |
| Payroll | Budget and balance reports | Safety issues |
| Training | Job openings | Holidays |
Discretionary Access Control (DAC) is the first model to introduce flexibility, it allows an administrator , or resource owner , to assign permissions on the groups below. Each file will have an owner, and if we want to extend the write permissions of the file to another user, then we add them to our group and we’re done. However, one thing that is important to keep note of is that DAC can still be susceptible to trojans. This is because a user may have been given permissions to run certain actions as the administrator, and so when they download this executable, they have just ransacked their computer … But if we had a role-based access control, as we shall see soon , then there wouldn’t be much of a chance for a user in that group to download things if they didn’t belong to any group which had power. Admins will need to keep tabs on people is what I’m trying to say. We could introduce the idea of two accounts : one with regular group privileges , and the second being the all-mighty admin account, but this idea is only done for admins so they don’t leak anything or if they accidentally download a trojan, that will be confined to execute whatever the account has had allotted to it.
Attribute-based Access Control (ABAC) utilise attributes of users to determine what resources they have access to. Essentially running on the logic of IF user.attribute == true THEN grant-access() . If the location of an employee is from their office, then we may allow them to login, otherwise not. We can right policies for particular users, such as their job roles, logged-on-status etc. It could be a specified action, like a low-power group user trying to access social media websites, we may decide to block that.
Now, there are actually two different access control mechanisms that use the acronym RBAC … one is for role based access control, which looks at a user’s job (admin, manager, team members etc), group and responsibility, whereas the other RBAC, rule based access control looks at the pre-configured settings and security policies to make all access decisions, sort of like an ACL would. Rules could literally be any old thing : what time of day it is, what is their terminal ID so I know that it might be a low-level user, the GPS coordinates of the requester. A nice thing about role-based access control, is that it doesn’t allow permission creep, which is where someone who hops departments gets access to both department data, if your role changes, then your permissions change; whereas with rule based access control, no matter who you are , if there is a schema overlap you might be able to grab some data you shouldn’t.
Using role-based (or job-based) access control we could take all listed privileges , so all role types , and then match them up to their respective functions. We can document all this within a matrix as shown in the example below:
| Role | Server Privileges | Project Privileges |
|---|---|---|
| Admins | All | All |
| Executives | None | All |
| Project Managers | None | All on assigned projects. No access on unassigned tasks |
| Team Members | None | Access for assigned tasks. Limited reads within the scope of their assigned tasks. No reads outside the scope of their assigned tasks. |
Biometrics
Biometrics refers to the science of establishing an individual’s identity based on some physical attribute. This translates to the “What you are” part of the authentication layers. There are three different error rates we need to consider when implementing biometric authentication mechanisms:
- False acceptance rate , this refers to unauthorised individuals who are granted access.
- False rejection, when the system doesn’t authorise an individual that is setup with the organisation.
- Crossover error rate, this is the key metric when trying to figure out whether or not we want to implement a given authentication mechanism: How high is the false acceptance versus the false rejection?
We can graph the two when we want to see how a particular authentication mechanism would work for us, and the cross-over error rate (CER) is where the two cross-over. You expect the FRR to go up, and this would reflect a stern whitelist system, whereas if it were low, you might wonder whether you had a great system, or you were letting everybody in; likewise a high FAR would be bad, the lower this is, the better your system is. If someone valid is falsely rejected, we can let them in. But if someone is falsely accepted, that’s where the fun starts.

Examples of biometric systems include:
- Fingerprint scanners
- Retina scanners
- Iris scanners
- Voice recognition
- Facial recognition
Tokens
Tokens are small little morsels of encrypted data, which can encapsulated in a hardware unit, which is mysteriously called a hardware token - this is a small device that could connect to our PC and it can authenticate us by generating a one-time passcode; conversely there is the software-based token which is where we use a unique piece of information, typically an incremented number to denote something like a session id, which is then passed on to the authorisation server. Tokens at this point are passed in plain-text, so what often happens is that tokens are signed, and the data itself is encrypted by something like AES-256 and then on the authorisation server the same algorithm is used to decrypt it.
Physical Access controls
Proximity cards and smart cards are the two main types, and both use embedded microchips to communicate with whatever physical medium grants them access, like a scanning box on the side of doors that workers “swipe”. Proximity cards hold little info, and pretty much just match the card identification number to access database information, so the “door” in this example knows who you are.
Smart cards can hold its own cryptographic key, which may even be signed by a certificate and this would be much harder to duplicate. It may be a programmable chip, and include biometric data.
Certificate-based authorisation
- PIV cards , Personal Identity Verification. Contactless smart cards used by Government workers.
- CACs , Common Access Cards. A credit-sized “smart” card used by US DoD workers. Inserted into a smart card reader, and authenticated with a PIN.
Certificate-based network authentication has it’s own standard, which is called IEEE 802.1x, and it states that all networked devices should have connect to a network , bearing a certificate that has been approved by the ownership authority.
4.4 Common Account Management Practices
So this chapter we will cover the standard account management practices you need to know for the Security+ exam. Account management is twofold, done by the account owner and the admin. It is the role of the admin to assign the right privileges, to make sure that people aren’t spontaneously locked out, to enforce a good password policy, and for the employees it’s important to follow said policies and use the account responsibly.
The main account management concept that pervades this section will be assignment, allocating the right privileges to the right accounts, and operating on the notion of least privilege which assigns the lowest level of privilege, where the account holder can still do their job.
Onboarding and offboarding will mean the system admin will have to scaffold an account template, and tune it to this particular new hire, or go through the process of deleting an account , disabling it or locking it out (depends on how long the employee is gone - maybe permanently - and business procedure). It might be that an employee moves across departments, this is another form of offboarding - from one section to the other - and it is important that the account this user has pertains to their role, they shouldn’t be able to privilege stack. This concept of offboarding should be extended to account checking, where offboarding is one such case where the account itself would be reviewed. For higher privileged accounts, like system admins, CTO accounts there may be a periodic review period where things like recertification happens, and such employees may have to come in, get a new security key or whatever and then go home. In less intensive companies, a query can just be ran through the payroll records to see all active employees. This review period may be the time when accounts of people that are no longer at the company are disabled or outright deleted, depends on their resignation, it could be a contractor that comes back…
Recertification is a part of regular account maintenance, which should be a process that organisations have in place, which is the routine screening of accounts, looking for suspicious attributes, powers and details that either a) shouldn’t belong to the account b) prevents the account from doing standard business functions and c) alters the privilege too great or too little.
Time of day restrictions might be put in place to limit and log traffic that is outside of a specified time that the corporation expects the account to be logged in to. Outside of this would be declared suspicious, and sometimes the account is just locked out and disabled , “until the bell strikes 9”. Just like time-based restrictions, there may be location-based policies that will see where an account is logging in from, and if it is outside of the office, then we assume foul play. It may also be that we have offices up and down the country and the same department within these two offices may assign different privileges to them, maybe the office in London does a lot more business than in New York and so employees have a greater wealth of resources that they need, more files they reference during their shift. Moreover, if an employee were to jump from one group to another, their privilege should change as their location does.
For new accounts, we should be following a standard naming convention, which should give enough information for an employee to remember, but the format shouldn’t be guessable to an attacker. Including the surname , so for instance nick.nicholson@company.org is better , to avoid repetition in the off-chance another Nick Nicholson comes in to the organisation. Moreover it should be future-proofed.
Group-based access control refers to managing accounts via groups, rather than individual users and new users that do join aren’t so unique that we have to do it on an individual basis, we can assign the same level of privilege to most people in a department, and then change it as and when they need it. By assigning based on things like role, it makes it a lot easier to scan through and manage all the departments, resources can be allocated and period reviews become easier.
Account Types
- User Accounts. Delimited by a unique user ID. These unique non-shared user IDs are vital for investigating access control issues. When users no longer require access, then their account may be terminated, but these accounts shouldn’t be removed immediately but should be disabled for a specified period instead. This is because we get what are called tombstones, which is where a system admin may be searching through old logs, trying to diagnose a problem, and instead of the user ID that was once there, they get a random string of information, and we have no idea which one of the accounts we deleted had been compromised, or been involved in some sort of insider plot. Accounts in general should be set to expire when a user is no longer authorised to use a system, but before removal resources should be reassigned.
- Shared accounts. Shared accounts may be between two employees, a general department account but most often it is between backup administrators. These accounts are harder to monitor and they are available across a wider number of systems; moreover it is paramount that the right privileges be set, only to execute a certain task, making it so the account can’t execute any other files apart from certain backup executables by doing
chmod 400on most files, and for task-related scripts doingchmod 444which means everyone on their can only execute the script, not in any way change it. - Service accounts. Very similar to shared accounts, service accounts should be restricted to perform certain tasks only, the only difference being that they do said tasks without the need for human interaction.
- Guest accounts. These are accounts that are made available to people that are temporarily joining forces with the organisation, like a visitor who wants internet access, we can assign him a guest WiFi network, or we could have a guest FTP server account which lists essential files to visitors, maybe policies who knows.
- Privileged accounts. Much like general user accounts, these are accounts that should have unique ID not increments like user IDs, it shouldn’t follow the user ID pattern, and it should have sufficient power to execute tasks that user accounts otherwise wouldn’t be able to. It is commonplace for an admin to also have a user account, as the two are completely separate, and this is good, so as not to give unnecessary power to a user account which just checks in , browses emails, writes up reports and presentations. This account is for running admin executables, making changes and seeing sensitive files. But with great power, comes even greater logging…
All about passwords
Accounts of any nature need to have a strong password, and we should have a password policy in place, to some degree , for every account type - obviously getting more rigorous and complex for each tier. The password itself , which is called the key , the key which unlocks your account should have a large key space, this space being the thing which encompasses the largest number of keys possible. So if we included in our policy that symbols were mandatory, we would increase the number of elements that someone could use , and hence each character in the password could be one of many options.
The formula for seeing the size of the key space is:
C^N ,
where C is the number of possible characters - so a-zA-Z and all symbols and numbers.
N is the length of the password itself.
Other important aspects of password policy is password recovery and resetting. It’s not uncommon for employees to forget their password, so we should make it easy to sort this problem out, but we want to make sure the person performing the request is authenticated and authorised. This can lead to all kinds of social engineering attacks where a hacker calls the help desk and says they can’t login, could you send me a reset email to johnndoe@gmail.com , the typo of which would lead us to the attacker’s email instead… The attack can be thwarted by asking “John” for his employee ID and the One-Time-Password (a code that is sent to your phone) to begin the resetting process. Note: I didn’t say this was a Vishing attack, this is because the attacker is calling to compromise an account, not trying to access personal information pertaining to the individual.
Onto another topic now , which is password administration. We could be an admin that sets up the following policy:
- The maximum password age is 30 days.
- The password minimum length is 14 characters.
- Passwords cannot be reused until five other passwords have been reused.
- Passwords must contain uppercase and lowercase letters, numbers and symbols.
But despite all this , employees are still using the same password that they are using more than a month ago… But how is this possible? Let’s go through this logically. They are using it for more than a month, which means they hit the maximum password age policy. It is at this point that they’re forced to make a new password, but here we can see that there is no real limit on how quickly they can churn through passwords. There is no minimum age. They can make five, in a matter of minutes, and then re-enter their remembered password and carry on as normal. The way we can stop this is either to make no passwords reusable, so making every each item in the password history unique and storing every password ever, or we can set a minimum password age for 2 weeks, 3 weeks or up to the 30 days which is the most time they are allowed, though this sounds a bit weird. After one week even they should’ve hopefully adjusted.
Password expiration is a silly concept though, as it makes it more difficult for employees to remember passwords, and they end up writing them down on sticky notes at their desk, violating their clean desk policy and making it easier for an insider to gain access. Remember , the password itself doesn’t expire, it is simply the time limit on how long they are expected to change…They could just add a one on the end, but there has to be another rule that stops us from reusing passwords, and that is to use password history, to see if this password is already in there, and so when the expiration is up they are forced to change to a different password , though let’s face it - if the password ends in a “1” then will just change it to a “2” …
Account Policy Enforcement
Now what we discussed above, these are akin to Memorandums of Understanding, a framework which is very useful, and a set of procedures which make business management a lot smoother, but without the agreement and enforcement, there is no point in even drafting such methodologies !
I am going to run through a means of enforcing account management i.e the storing , managing (overseeing) , and logging of accounts via a Windows environment. To establish this sort of credential management we can use what are called Group Policy Objects, and we have heard of group-based policy before, it is simply the insertion of our policies onto the client machine via the enterprise control. This can be configured by technicians who setup the PC in the first place, but admins can also go over the network and change these domain settings. These are slightly different to one’s local configuration, remember that the corporate network is nevertheless a network, and through it admins will modify whatever it is that the client computer has exposed to it.
Settings that can be changed through GPOs are password length and complexity requirements for example, of which it would be a good recommendation to bump the character length to at least 8 characters and to have : Uppercase and lowercase letters, numbers and a special character like @ , ! , () etc. Still on the tangent of password security, password history is a good setting to have enabled, as it logs every password a user has ever used, encrypted obviously , and then this can allow us to enforce password reuse, which is to stop users from ever using a password that they have done before. And I don’t just mean on their client machine, they need to understand the policy that they must always update to a fresh password when they are given a new machine - otherwise when a breach occurs , hackers may try these newly acquired credentials and see where they work, the likelihood of a breach goes up as more and more common passwords are added to this chunky wordlists for cracking. Our password lockout configuration will stop active attempts, but if they manage to snatch the hash, it’s practically game over.
Account lockout settings can also be configured, so things like password attempts can induce an account lockout, and the lockout time can be defined to 30 minutes, an hour , two hours! Depending on the strictness of the company, they may need to go through security questions, or they need to call up the help desk and ask for a password reset.
Account recovery is a concept that will typically apply to single users, and having groups to template default configurations is important , as admins can then assign unique values like this. Say someone has to undergo a pretty heavy surgery, then they may be out of work for six months. Standard procedures say that after 90 days of account inactivity the account should be deleted. But no ! They will come back, and to disable this logic is important, so the user keeps his/her files and folders in tact for when they return.
References
Group Policy editor on local windows machines
Complete Windows Networking guide
Windows Password Policies
Windows Audit Policies
Windows Access Policies
https://docs.microsoft.com/en-us/windows-server/networking/technologies/ipam/create-an-access-policy